MambaOut-Do We Really Need Mamba for Vision?
mamba是继transformer之后大火的结构之一。也涌现了各种mamba,各种领域的mamba。本博客之前也介绍了这一算法。
出自NUS的Weihao Yu, Xinchao Wang等人提出了纯卷积的mamaout意图打败mamba。
MambaOut 模型在 ImageNet 图像分类上超越了所有视觉 Mamba 模型,表明 Mamba 对于该任务确实是不必要的。至于检测和分割,MambaOut 无法与最先进的视觉 Mamba 模型的性能相媲美,这展示了 Mamba 在长序列视觉任务中的潜力。
论文:arxiv
代码:github
结构

概念讨论
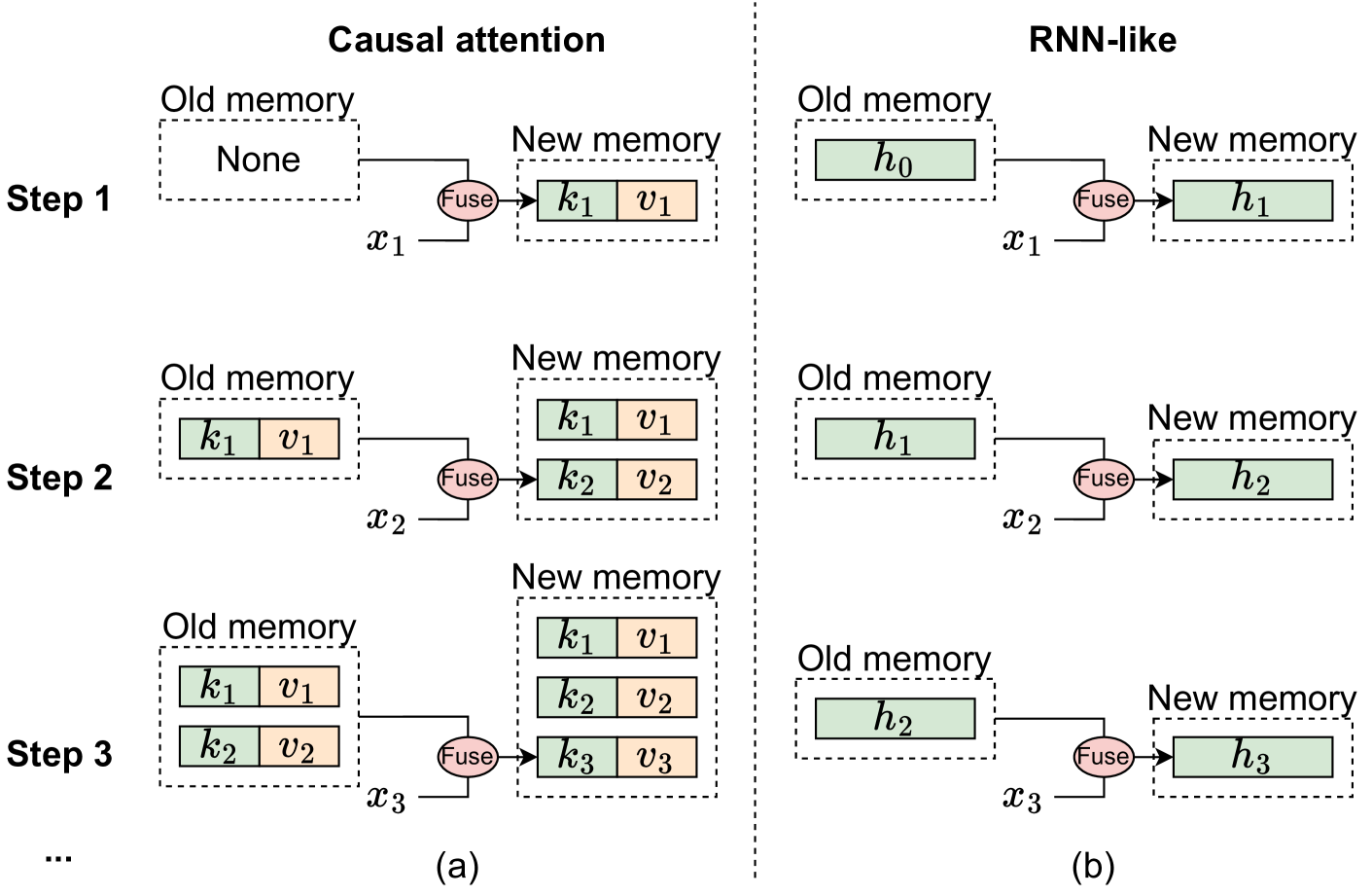
从记忆角度来看因果注意力和类 RNN 模型的机制说明,其中$x_i$ 表示第 i 步骤的输入标记。 (a) 因果注意力将所有先前标记的键 和值 存储为内存。通过不断添加当前 token 的 key 和 value 来更新内存,因此内存是无损的,但缺点是随着序列的延长,整合旧内存和当前 token 的计算复杂度会增加。因此,注意力可以有效地管理短序列,但可能会遇到较长序列的困难。
相反,类似 RNN 的模型将先前的标记压缩为固定大小的隐藏状态 ℎ ,用作内存。这种固定大小意味着 RNN 内存本质上是有损的,无法与注意力模型的无损内存容量直接竞争。尽管如此,类似 RNN 的模型在处理长序列时可以表现出明显的优势,因为无论序列长度如何,将旧内存与当前输入合并的复杂性保持不变。
总之,Mamba 非常适合具有以下特征的任务:
• 特征1:任务涉及处理长序列。
• 特征2:任务需要因果标记混合模式。
是否适合
接下来,论文将讨论视觉识别任务是否表现出这两个特征。
视觉识别任务的序列是否很长
对于ImageNet上的图像分类,典型的输入图像大小为 224$^{2}$,从而产生块大小为 16$^{2}$的 14$^{2}=196$标记。显然,196 远小于$\tau_\mathrm{small}$和$\tau_\mathrm{base}$ ,表明 ImageNet 上的图像分类不符合长序列任务的条件。
对于 COCO 上的对象检测和实例分割,推理图像大小为$800\times1280$,对于 ADE2oK 上的语义分割,推理图像大小为$512\times2048$ ,令牌数量约为4K,给定补丁大小$16^2$。从$4K>\tau_\mathrm{small}$和$4K\approx\tau_\mathrm{base}$开始,COCO上的检测和ADE2oK上的分割都可以被认为是长序列任务。
视觉识别任务需要因果标记混合模式吗
作者指出,完全可见的令牌混合模式允许不受限制的混合范围,而因果模式则限制当前令牌只能访问先前令牌的信息。视觉识别被归类为理解任务,其中模型可以立即看到整个图像,从而消除了对令牌混合的限制。对令牌混合施加额外的限制可能会降低模型性能。
实验验证
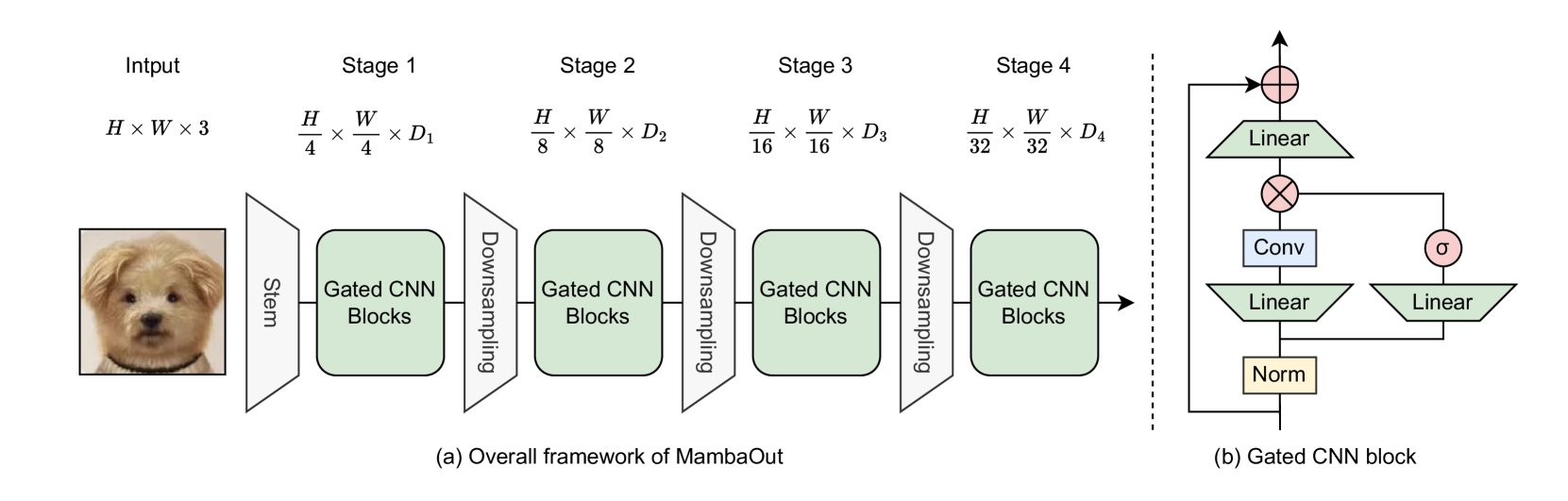
Gated CNN 块的算法的PyTorch 代码:
1 | |
分类
下表显示了224*224分辨率下模型在ImageNet上的性能。我们的MambaOut模型采用gate CNN块[60]。Mamba区块源自Gated CNN区块,包含了一个额外的SSM(状态空间模型)。很明显,视觉mamba模型不如MambaOut的性能,更不用说超越最先进的卷积或卷积注意力混合模型了。注意,vmamba9将mamba块的元架构修改为MetaFormer,不同于其他可视化mamba模型和MambaOut
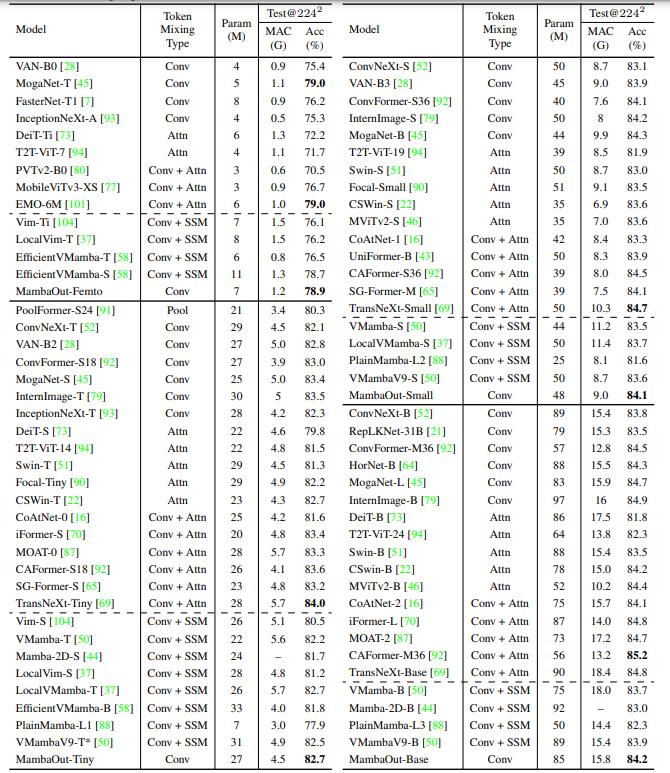
分割