FINDING ADVERSARIALLY ROBUST GRAPH LOTTERY TICKETS
《FINDING ADVERSARIALLY ROBUST GRAPH LOTTERY TICKETS 》NeurIPS 2023&ICLR 2024
相关工作
Graph Lottery Ticket Hypothesis
The Lottery Ticket Hypothesis
该论文首先提到了ICLR 2019最佳论文:The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks。该论文提出了彩票假说:密集的、随机初始化的、前馈网络包含子网络(中奖票),这些子网络在孤立地训练时,在类似数量的迭代中达到与原始网络相当的测试精度。
具体而言,他的训练策略如下:

《Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask》也有类似的内容。展示了为什么将权重设置为零很重要,如何使用符号来进行重新初始化的网络训练,以及为什么掩蔽的行为类似于训练。最后,我们发现了超级掩码的存在,这些掩码可以应用于未经训练的随机初始化网络,以生成性能远远优于偶然的模型(MNIST 上为 86%,CIFAR-10 上为 41%)。
ICLR2020 的《Proving the Lottery Ticket Hypothesis: Pruning is All You Need宣称证明了The Lottery Ticket Hypothesis。一句话概括:只要对随机初始化的神经网络做个好剪枝,不怎么训练也能有个好效果。
Pruning is All You Need!
该文证明的结论是:
Fix some target fully-connected ReLU-network F of width k, depth d and input dimension n.Fix$\delta>0$.Then,arandomly-initialized network $G$ of width $poly(d,n,k,1/\epsilon,\log(1/\delta))$ and depth 2d, has w.p. $\geq1-\delta$ a subnetwork $\tilde{G}$ that approximates F up to $\epsilon.$
简单的说,给定一个深度为d的Relu目标网络。那么一个深度为2d,且足够宽的随机网络里,必然可以找到一个可以逼近目标网络的子网络。
具体证明可见刘斯坦的解答
In Graph
《A Unified Lottery Ticket Hypothesis for Graph Neural Networks》一文将LTH应用在了GNN上。
具体而言,在端到端训练过程中,UGS分别对邻接矩阵和GNN模型权值应用两个可微二元掩模张量。训练完成后,移除最小大小的元素,将相应的掩码位置更新为0,分别从邻接矩阵和GNN中去除低评分的边和权重。然后将稀疏GNN权重参数倒绕到其原始初始化。(类似于原始的LTH)
实验结果表明,UGS可以在不影响预测精度的前提下显著降低推理计算成本。在这项工作中,我们的目标是为受到对抗性扰动的数据集找到glt。当我们将UGS算法直接应用于摄动图时,glt的性能精度与干净的glt相比明显较低,这需要开发新的优化方法来寻找对抗鲁棒的glt。
分析对抗性攻击对图属性的影响
像MetaAttack、PGD和PR-BCD这样的对抗性攻击通过引入新边或删除现有边来毒害图结构,导致原始图属性发生变化。
我们分析了干净边和对抗边连接的节点在属性特征上的差异。
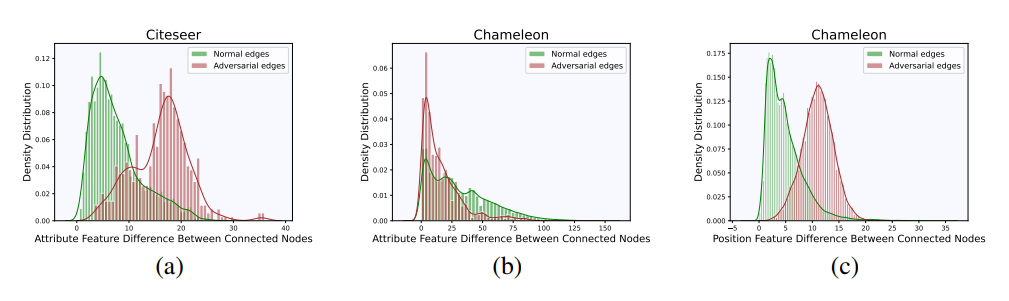
图a和图b描述了受PGD攻击的homophilic和 heterophilic图数据集中连接节点属性特征差的密度分布。在同态图中,攻击倾向于连接属性特征差异较大的节点。防御技术可以潜在地利用这些信息来区分图中的良性和敌对边缘。然而,这不是 heterophilic图的情况。相反,我们利用节点的位置特征,使用像DeepWalk这样的位置编码技术(Perozzi等人,2014)。有趣的是,从图c中我们可以看到,在heterophilic图中,攻击倾向于连接位置特征差较大的节点。ARGS使用这些图的属性来迭代地从homophilic和 heterophilic图中修剪对抗性边。
方法
$\mathcal{L}$
总所周知,两层的GCN可以表示为
$$
Z=f({ A, X },\Theta)= \mathcal{S}(\hat{A} \sigma ( \hat A X W_{(0)}) W_{(1)})
$$
设计了一个transductive semi-supervised node classification (SSNC) loss:
$$
\mathcal{L} _0 (f(\left{A, X\right}, \Theta))=-\sum _ {l \in \mathcal{Y} _{TL}} \sum _{j=1} ^C Y _{l_j} log( Z {l_j})
$$
其中$\mathcal{Y}{TL}$是训练节点的索引,C是类总数,$Y_l$是$v_l$one hot 标签。
posion 攻击者的目标是找到一个最优的扰动A ‘,欺骗GNN做出错误的预测。这可以表述为一个双层优化问题(Zugner et al., 2018;zugner & gunnemann, 2019):
$$
arg \max\mathcal{L}{atk}(f(\left{A’,X\right},\Theta ^\ast))\
A’\in\Phi(A)\
\mathrm{s.t.}\quad\Theta^{\ast}=\arg\min{\Theta}\mathcal{L}{0}(f(\left{A’,X\right},\Theta))
$$
其中$\Phi(A)$是满足$\frac{|A’-A|{0}}{|A|{0}}\leq\Delta$的领接矩阵。$\mathcal{L}{atk}$ 是攻击loss函数,$\Delta$ 是 perturbation rate,$\Theta ^\ast$是摄动图上GNN的最优参数。
为了帮助消除对抗边和鼓励特征平滑,对于homophilic graphs:
$$
\mathcal{L}{fs} (A’,X)=\frac{1}{2} \sum{i,j=1}A_{ij}’ (x_i-x_j)^2
$$
对于heterophilic graphs:
$$
\mathcal{L}{fs}(A’)=\frac{1}{2}\sum{i,j=1}A_{ij}’(y_{i}-y_{j})^{2}
$$
以上有点像dirichlet energy。
dirichlet energy:
$$
tr(x^\top Lx)=|\nabla_Gx|_2^2=\frac{1}{2}\sum _{i,j}W[i,j] (x[j]-x[i])^2
$$
进一步归一化:
$$
tr(x^\top Lx)=|\nabla_Gx|_2^2=\frac{1}{2}\sum _{i,j}W[i,j] (\frac{x[j]}{\sqrt{1+d_j}}-\frac{x[i]}{\sqrt{1+d_i}})^2
$$
(上式来自《Dirichlet Energy Constrained Learning for Deep Graph Neural Networks》)或
$$
tr(x^\top Lx)=|\nabla_Gx|_2^2=\frac{1}{4}\sum _{i,j}W[i,j]|\frac{x[j]}{\sqrt{d_j}}-\frac{x[i]}{\sqrt{d_i}}|_2^2
$$
(上式来自《A Fractional Graph Laplacian Approach to Oversmoothing》)其中d为节点的度。
其中yi∈R P为输入图G上运行DeepWalk算法(Perozzi et al., 2014)得到的节点i, j的位置特征,P为节点位置特征个数。
另外,作者还训练了一个简单的两层MLP。mlp只使用节点特征进行训练。然后我们使用训练好的MLP来预测测试节点的标签。称这些标签为伪标签。最后,利用MLP预测置信度较高的测试节点计算测试节点CE损失项。
设$Y_{P L}$为MLP预测置信度较高的测试节点集,$Y_{mlp}$为MLP的预测值。CE损失为:
$$
\mathcal{L}1(f({A’,X},\Theta))=-\sum{l\in\mathcal{Y}{TL}}\sum{j=1}^CY_{mlp_{l_j}}\log(Z_{l_j})
$$
最终loss为:
$$
\mathcal{L}{ARGS}=\alpha\mathcal{L}{0}(f({m_{g}\odot A’,X},m_{\theta}\odot\Theta))+\beta\mathcal{L}{fs}(m{g}\odot A’,X)\+\gamma\mathcal{L}{1}(f({m{g}\odot A’,X},m_{\theta}\odot\Theta))+\lambda_{1}||m_{g}||{1}+\lambda{2}||m_{\theta}||{1}
$$
其中,$\alpha$和$\gamma$设置为1。$m_g$用于领接矩阵,$m\theta$用于模型权重。

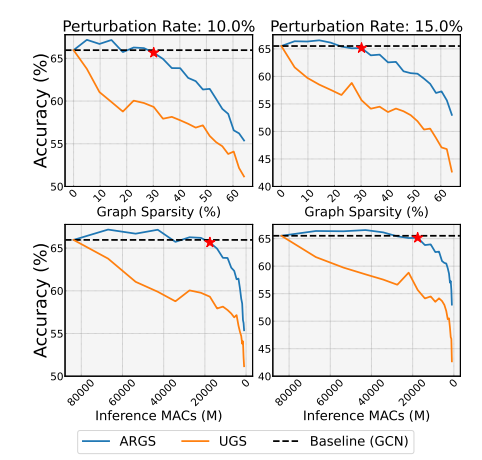
实验结果
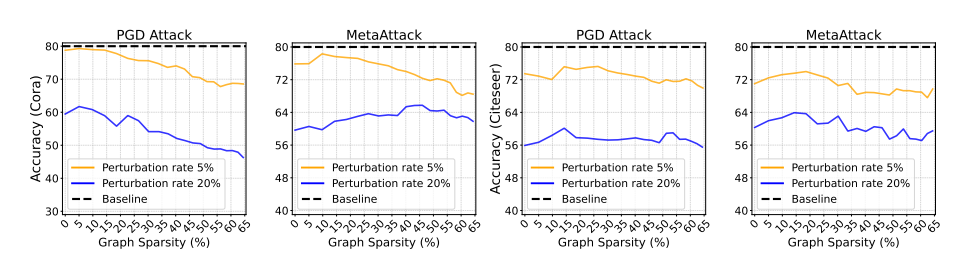
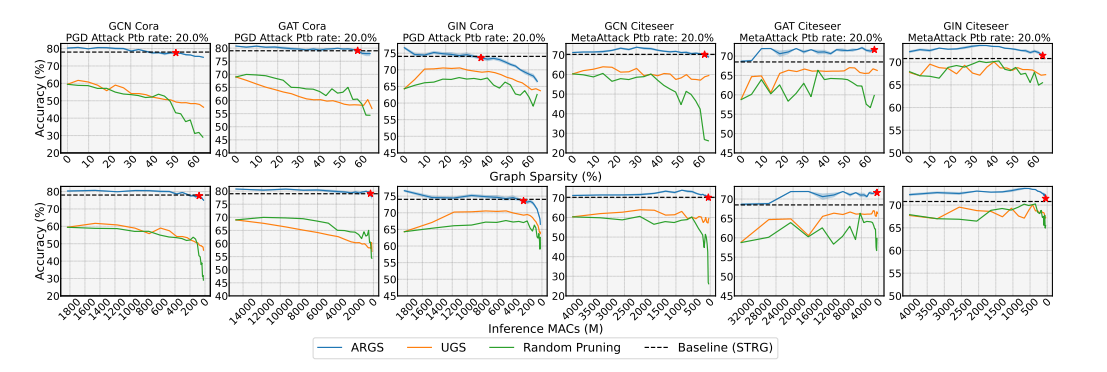
Inference MACs(Multiply-Accumulate Operations)是指推断过程中的乘累加操作数量。
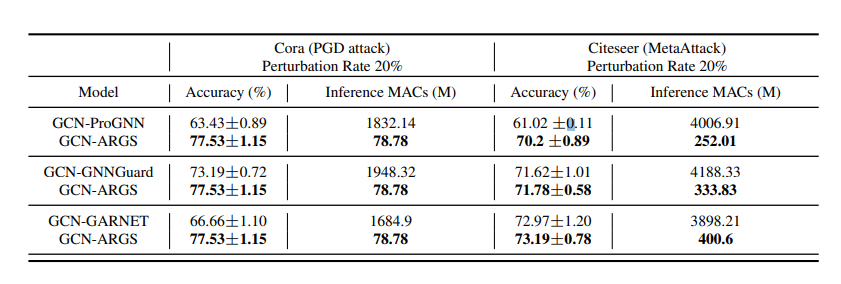
在大规模图数据集中:
消融实验:
