Mamba---Linear-Time Sequence Modeling with Selective State Spaces
论文两位作者Albert Gu和Tri Dao,博士都毕业于斯坦福大学,导师为Christopher Ré。
Albert Gu现在是CMU助理教授,多年来一直推动SSM架构发展。他曾在DeepMind 工作,目前是Cartesia AI的联合创始人及首席科学家。
Tri Dao,以FlashAttention、FlashDecoding系列工作闻名,现在是普林斯顿助理教授,和Together AI首席科学家,也在Cartesia AI担任顾问。
Code:github
SSM指的是结构化状态空间序列模型(Structured state space sequence models,S4)
S4模型可由四个参数 $(\Delta,A,B,C)$ 定义,他们分两个阶段定义序列到序列的转换。
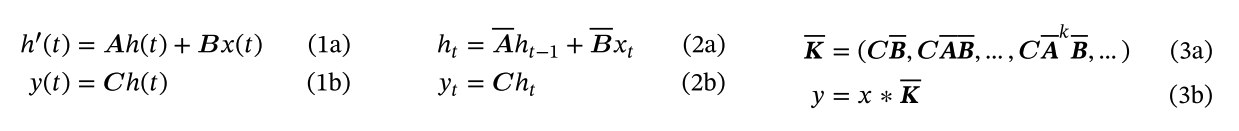
离散化有
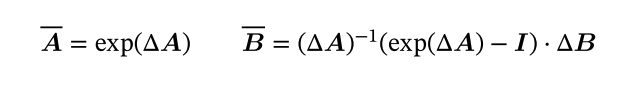
离散化证明:
$$
\dot{x}(t)=Ax(t)+Bu(t) \
y(t)=Cx(t)+Du(t)
$$
为了方便,我们对$e^{-At}x(t)$进行积分,我们得到:
$$
x(t)=e^{At}x(0)+\int_0^te^{A(t-\tau)}Bu(\tau)d\tau
$$
我们需要对上述进行离散化。

在参数从 (∆,A,B,C) ↦ (A,B,C) 转化之后,模型可以通过两种方式计算,一种是线性递归 (式2) (使用RNN),另一种是全局卷积 (3) (使用CNN)。
通常在训练时使用卷积模式 (式3) (提前看到整个输入序列),推理时使用递归模式 (式2) (每次看到一个时间步的输入)。
线性时不变性(Linear Time Invariance,LTI)
S4 的状态模型参数 (Δ,A,B,C) 在所有时间步中都是固定不变的,这一特性被称为线性时不变性。LTI 是递归和卷积的基石,为构建序列模型提供了一个简化但功能强大的框架。
迄今为止,所有结构化 SSM 都是 LTI 模型,因为存在基本的效率限制。然而,本文工作的一个核心观点是,LTI 模型在对某些类型的数据进行建模时具有根本性的局限性,本文的技术贡献在于消除 LTI 限制,同时克服效率瓶颈。
一些可以被认为是SSM的结构
Linear attention: 线性注意力,它是自注意力的近似,涉及一个递归,可以看作是一个退化的线性 SSM。
H3: 它在S4的基础上进行了扩展;可以被看作是一种由两个门控连接夹着一个 SSM 的架构(如下图)。H3还在主SSM层之前插入了一个标准的局部卷积,将这部分定义为一个shift-SSM。
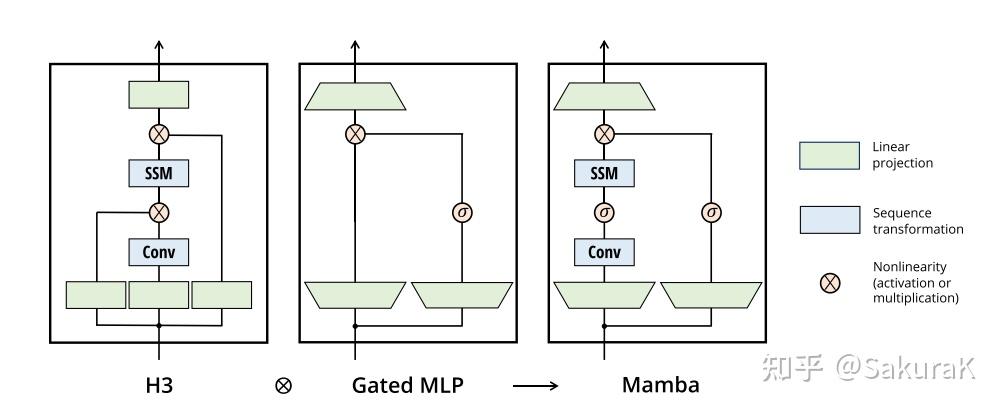
Hyena: 使用与 H3 相同的架构,但用 MLP 参数化全局卷积取代了 S4 层。
RetNet: 在架构中增加了一个额外的门,并使用更简单的 SSM,允许另一种可并行计算的路径,使用多头注意力(MHA)的变体来代替卷积。
RWKV: 是最近基于另一种线性注意近似(attention-free Transformer)设计的用于语言建模的 RNN。它的主要 “WKV “机制涉及 LTI 递归,可视为两个 SSM 的比值。
其他的方法还有S5、QRNN、SRU等。
S6的提出
S4是线性时间不变(LTI)模型,具有局限性。从递归模型的角度来看,它们恒定的动态(例如 $\bar{A},\bar{B}$ 不能使它们从上下文中选择正确的信息,或以输入依赖的方式影响沿序列传递的隐藏状态。从卷积模型的角度来看,虽然全局卷积可以解决标准复制任务,但在处理需要内容意识的选择性复制任务时则存在困难,因为输入到输出之间的间距是变化的,无法用静态卷积核建模。
序列模型的效率与有效性之间的权衡由它们压缩状态的能力决定:高效的模型必须有一个小的状态,而有效的模型必须包含所有必要的上下文信息。作者提出,构建序列模型的一个基本原则是选择性,或者说具有上下文意识的能力,专注于或过滤掉输入到序列状态的信息。特别是,选择机制控制信息如何在序列维度上传播或相互作用。(Mamba就像是每次参考前面所有内容的一个概括,越往后写对前面内容概括得越狠,丢掉细节、保留大意)
于是有了以下改动:

其中
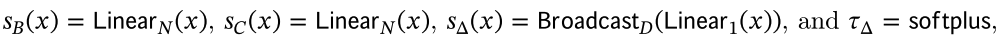
模型从时不变变成了时可变。
由于失去了LTI的性质,不能像之前的S4一样通过FFT来训练了。本文提出了IO-aware的parallel scan(一种memory bounded算子)算法来进行高效训练,降低整体的读写量从而提高wall-time efficiency。上面提到的outer product的参数化方式也对降低整体读写量很有帮助(大致思路是 (A¯,B¯)(\bar{A}, \bar{B})(\bar{A}, \bar{B}) 在SRAM里面on-the-fly算出来,避免materialization带来的读写开销)
简化的 SSM 架构
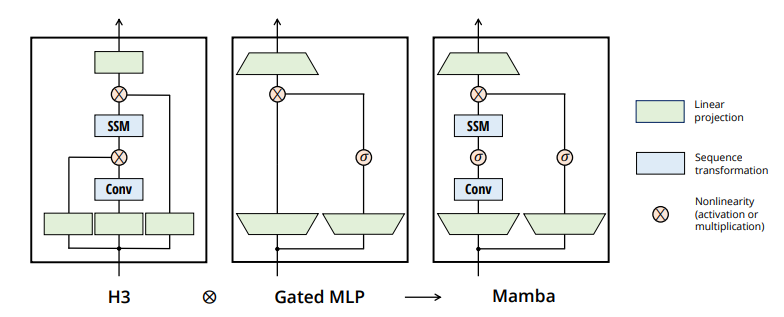
本文的简化区块设计结合了 H3 区块(大多数 SSM 架构的基础)和现代神经网络中无处不在的 MLP 区块。这只是简单地重复 Mamba 模块,而不是交错使用这两个模块。与 H3 模块相比,Mamba 用激活函数取代了第一个乘法门。与 MLP 模块相比,Mamba 在主分支上增加了一个 SSM。对于 $\sigma$ ,使用 SiLU / Swish 激活。
Mamba架构通过一个可控的扩展因子 E 来扩大模型维度 D。在每个块中,大部分参数(3ED^2)用于线性投影(2ED^2用于输入投影,ED^2用于输出投影)。与线性投影相比,SSM的参数(Δ, B, C 的投影和矩阵 A)数量要少得多。通过重复这个块,并与标准的归一化和残差连接交错,构成了Mamba架构。
在实验中,扩展因子 E 总是固定为2,使用两层堆叠的块来匹配Transformer的交错多头注意力(Multi-Head Attention, MHA)和MLP块的 12D^2 参数。采用SiLU/Swish激活函数,使得Gated MLP成为流行的“SwiGLU”变体。最后,受到RetNet在类似位置使用归一化层的启发,还使用了一个可选的归一化层(选择了LayerNorm)。
参数的影响
- 参数Δ的作用: 它控制着模型对当前输入 x_t 的关注程度,以及应该保留多少历史状态信息。调节 Δ 的大小,可以模拟不同的系统行为,从完全关注当前输入到完全保留历史状态,实现对输入的选择性关注。Δ 在SSMs中起着类似于RNN门控信号的作用,如在定理1中提到的 g_t,但在SSMs的框架下提供了一种更一般化的形式。 当 Δ 很大时,模型会重置状态 h,这相当于让模型更多地关注当前的输入 x,而非之前的状态。当 Δ 很小时,模型保持现有状态 h 的持久性,对当前的输入 x 给予较少的关注,从而忽略它。 SSMs 可以被看作是一个连续系统通过时间步长 Δ 离散化后的结果。在这个离散化的连续系统中,大的 Δ(趋向于无穷)意味着系统在较长时间内专注于当前输入,相当于“选择”了当前输入并忘记了当前状态。相反,小的 Δ(趋向于零)意味着当前输入是短暂的,可以被忽略。
- 参数A的作用: 虽然理论上 A 也可以具备选择性,但 A 对模型的主要影响是通过它与 Δ 的相互作用来实现的(通过离散化公式 A=exp(ΔA) )。作者认为,只要 Δ 具有选择性,就可以保证整个模型的选择性,而且 Δ 是提高模型性能的关键。为了保持模型的简洁性,作者选择不让 A 参数具备选择性。
- 参数 B 和 C 的作用: 选择性最重要的特性是过滤掉无关信息,从而将序列模型的上下文压缩成有效的状态。在 SSM 中,修改 B 和 C 使其具有选择性,可以使模型能够更精细地控制输入和状态的流动。
- B 控制着输入 x_t 是否被引入到状态 h_t 中,即选择性地决定哪些输入对状态的更新至关重要。
- C 影响着状态 h_t 如何转化为输出 y_t,即如何基于当前的状态信息生成最终的输出。
这意味着,SSM可以基于当前处理的数据内容以及已经编码在隐藏状态中的上下文信息,来动态地调整其内部状态的更新方式和输出。这增加了模型处理序列数据时的灵活性和有效性,因为它可以根据数据的具体特征和任务需求来优化信息流。
实验结果
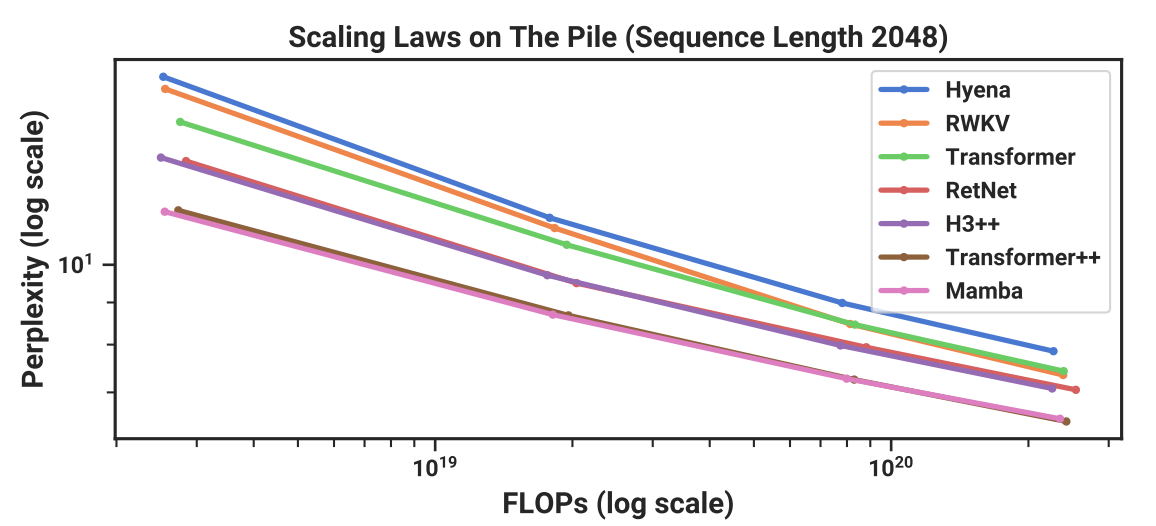
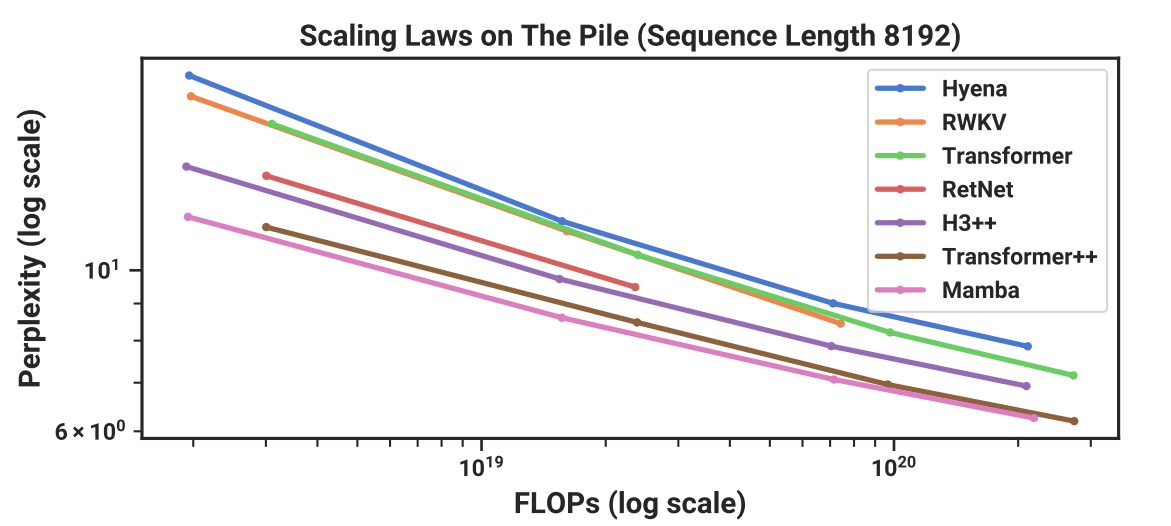
其中Transformer++指的是带有Rope和SwiGLU的版本(i.e., LLaMa用的)。
结果中也有国人研发的号称取代transformer的RWKV。
而这些模型只能匹敌普通的transformer,只有mamba才能与transformer++匹敌。