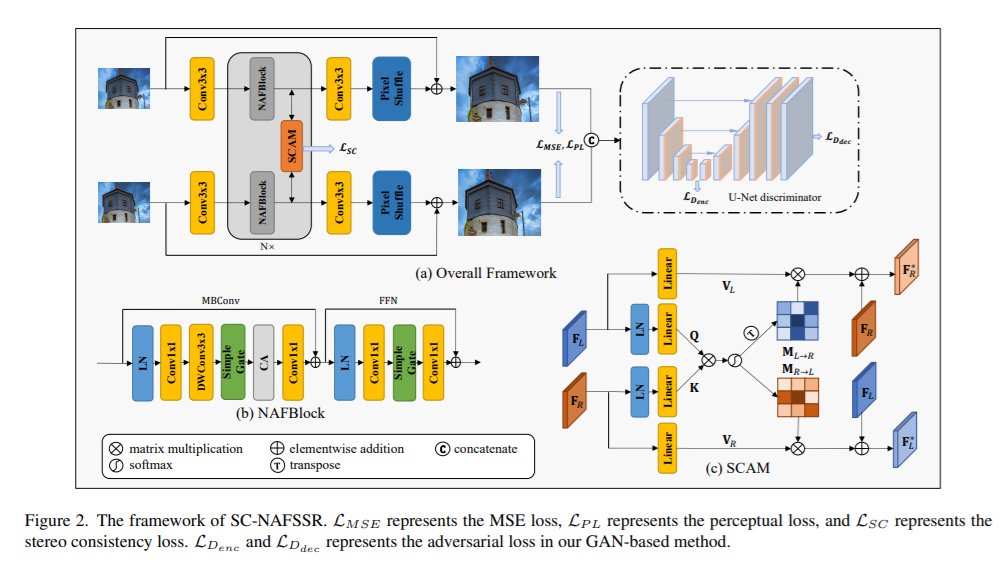
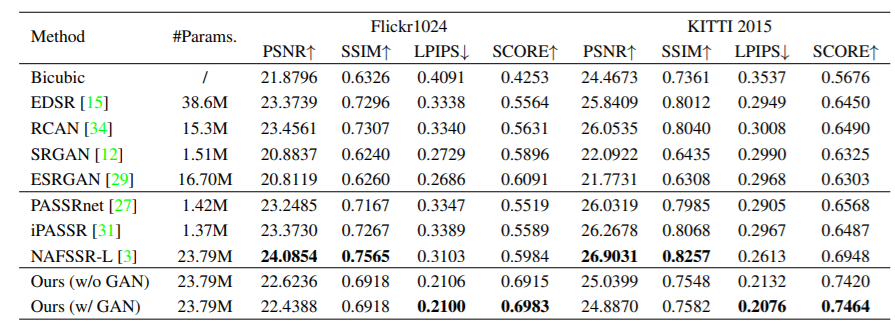
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| class SCAM(nn.Module):
'''
Stereo Cross Attention Module (SCAM)
'''
def __init__(self, c):
super().__init__()
self.scale = c ** -0.5
self.criterion = nn.L1Loss()
self.norm_l = LayerNorm2d(c)
self.norm_r = LayerNorm2d(c)
self.l_proj1 = nn.Conv2d(c, c, kernel_size=1, stride=1, padding=0)
self.r_proj1 = nn.Conv2d(c, c, kernel_size=1, stride=1, padding=0)
self.beta = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)
self.gamma = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)
self.l_proj2 = nn.Conv2d(c, c, kernel_size=1, stride=1, padding=0)
self.r_proj2 = nn.Conv2d(c, c, kernel_size=1, stride=1, padding=0)
def forward(self, x_l, x_r, LR_left, LR_right, loss):
Q_l = self.l_proj1(self.norm_l(x_l)).permute(0, 2, 3, 1)
Q_r_T = self.r_proj1(self.norm_r(x_r)).permute(0, 2, 1, 3)
V_l = self.l_proj2(x_l).permute(0, 2, 3, 1)
V_r = self.r_proj2(x_r).permute(0, 2, 3, 1)
b, h, w, c_ = Q_l.shape
attention = torch.matmul(Q_l, Q_r_T) * self.scale
attention_T = attention.permute(0, 1, 3, 2)
M_right_to_left = torch.softmax(attention, dim=-1)
M_left_to_right = torch.softmax(attention_T, dim=-1)
V_left_to_right_mask = torch.sum(M_left_to_right.detach(), 2) > 0.1
V_left_to_right_mask = morphologic_process(V_left_to_right_mask.view(b, 1, h, w))
V_right_to_left_mask = torch.sum(M_right_to_left.detach(), 2) > 0.1
V_right_to_left_mask = morphologic_process(V_right_to_left_mask.view(b, 1, h, w))
M_left_right_left = torch.matmul(M_right_to_left, M_left_to_right)
M_right_left_right = torch.matmul(M_left_to_right, M_right_to_left)
F_r2l = torch.matmul(M_right_to_left, V_r)
F_l2r = torch.matmul(M_left_to_right, V_l)
F_r2l = F_r2l.permute(0, 3, 1, 2) * self.beta
F_l2r = F_l2r.permute(0, 3, 1, 2) * self.gamma
loss_h = self.criterion(M_right_to_left[:, :-1, :, :], M_right_to_left[:, 1:, :, :]) + \
self.criterion(M_left_to_right[:, :-1, :, :], M_left_to_right[:, 1:, :, :])
loss_w = self.criterion(M_right_to_left[:, :, :-1, :-1], M_right_to_left[:, :, 1:, 1:]) + \
self.criterion(M_left_to_right[:, :, :-1, :-1], M_left_to_right[:, :, 1:, 1:])
loss_smooth = loss_w + loss_h
Identity = torch.autograd.Variable(torch.eye(w, w).repeat(b, h, 1, 1).to(Q_l.device), requires_grad=False)
loss_cycle = self.criterion(M_left_right_left * V_left_to_right_mask.permute(0, 2, 1, 3), Identity * V_left_to_right_mask.permute(0, 2, 1, 3)) + \
self.criterion(M_right_left_right * V_right_to_left_mask.permute(0, 2, 1, 3), Identity * V_right_to_left_mask.permute(0, 2, 1, 3))
LR_right_warped = torch.bmm(M_right_to_left.contiguous().view(b * h, w, w), LR_right.permute(0, 2, 3, 1).contiguous().view(b * h, w, 3))
LR_right_warped = LR_right_warped.view(b, h, w, 3).contiguous().permute(0, 3, 1, 2)
LR_left_warped = torch.bmm(M_left_to_right.contiguous().view(b * h, w, w), LR_left.permute(0, 2, 3, 1).contiguous().view(b * h, w, 3))
LR_left_warped = LR_left_warped.view(b, h, w, 3).contiguous().permute(0, 3, 1, 2)
loss_photo = self.criterion(LR_left * V_left_to_right_mask, LR_right_warped * V_left_to_right_mask) + \
self.criterion(LR_right * V_right_to_left_mask, LR_left_warped * V_right_to_left_mask)
loss += 0.0025 * (loss_photo + 0.1 * loss_smooth + loss_cycle)
return x_l + F_r2l, x_r + F_l2r, LR_left, LR_right, loss
|