Boosting Text-to-Image Diffusion Models with Fine-Grained Semantic Rewards
该论文来自同级的fga同学。fga同学是一位我挺佩服的同学。
论文地址:https://arxiv.org/abs/2305.19599
共同一作:fga和来自穆罕默德·本·扎耶德人工智能大学(MBZUAI)的Zutao Jiang
其他作者还包括来自华为诺言方舟实验室的几位和梁晓丹老师。
不知道这篇论文会在哪里发表(目前还是arxiv),也不能断定这篇论文是否具有较大的学术阅读价值,但我认为阅读这篇论文能让我见识一下自己与别人的差距。
这篇论文中,作者提出了FineRewards,通过引入两种新的细粒度语义奖励:caption奖励和SAM奖励,来改善文本到图像扩散模型中文本和图像之间的对齐。
此外,还采用了集合奖励排序学习策略,使多个奖励函数能够集成,以共同指导模型训练。
模型示意图
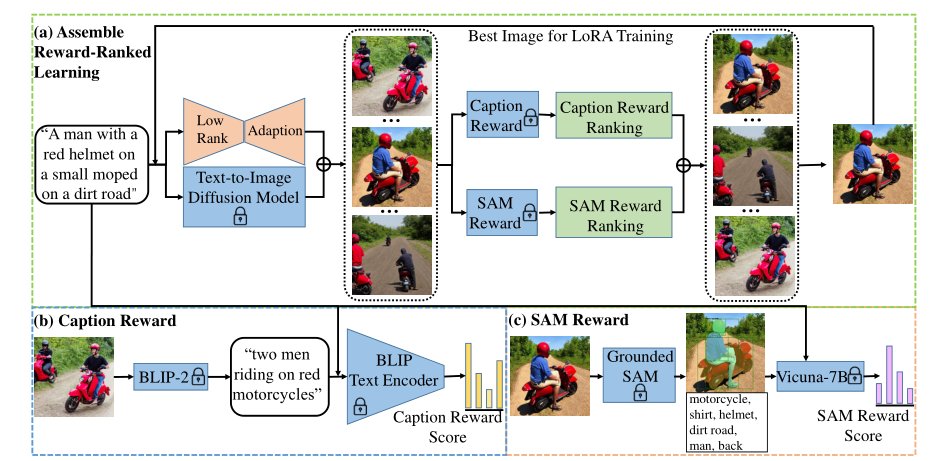
diffusion模型结合了2021年Lora和2023年的SAM
Caption Reward:这里用的是BLIP-2模型,计算分数为余弦相似度。
SAM Reward:
具体来说,我们首先使用Grounded SAM生成的图像,并获得每个掩码的语义类别标签$L=^n_i=1$,其中n表示掩码/标签的数量。然后使用大型语言模型,即Vicuna-7B,基于所提供的提示来评估所描述的场景,并基于每个类别标签出现在场景中的可能性为每个掩码分配奖励分数。每个mask $s_i$的奖励分数根据以下标准确定:

最后:
$$
R_{sam}=\frac{1}{n}\sum^n_{i=1}s_i
$$
使用的prompt:
Please assess the described scene based on the provided prompt and determine the likelihood of each tag appearing in the scene. Assign a score to each tag according to the following criteria: If a tag is certain to appear, assign a score of 3. If a tag may appear, assign a score of 2. If a tag is unlikely to appear, assign a score of 1.
额…..其实有点奇怪….为啥这里要用LLM….这感觉就是个文本相似度判定…..
**选择图像:**在后续的选择中使用排名相加而不是两个reward相加
想法:
1.使用Vicuna有种杀鸡用牛刀的感觉
2.文中的选择图像的方法也就是Assemble Reward-Ranked Learning,使用排名相加其实也感觉由于分数相加,但感觉不如gaussrank相加。
3.文中的caption由BLIP-2生成,但是BLIP生成的比较简短,且不一定贴近prompt,是不是使用一些更先进的方法效果还能进一步提升呢?比如。但是注意到SAM生成的tag其实很简短,那是不是使用BLIP实际上是可行的呢,还是说引入更相似能增加模型的泛化性呢?