Voice Conversion With Just Nearest Neighbors
来自《Voice Conversion With Just Nearest Neighbors》
demo地址:https://bshall.github.io/knn-vc/
代码地址:https://github.com/bshall/knn-vc
简介:任意语音转换旨在将源语音转换为目标语音,仅以目标说话者的几个例子为参考。最近的方法产生了令人信服的转换,但代价是增加了复杂性——使结果难以复制和构建。相反,我们保持简单。我们提出了k近邻语音转换(kNN-VC):一种简单而有效的任意到任意转换方法。首先,我们提取源语音和参考语音的自监督表示。为了转换为目标说话者,我们将源表示的每个帧替换为其在参考中的最近邻居。最后,预训练的声码器从转换后的表示中合成音频。客观和主观评价表明,kNN-VC以与现有方法相似的可懂度分数提高了说话人的相似性。
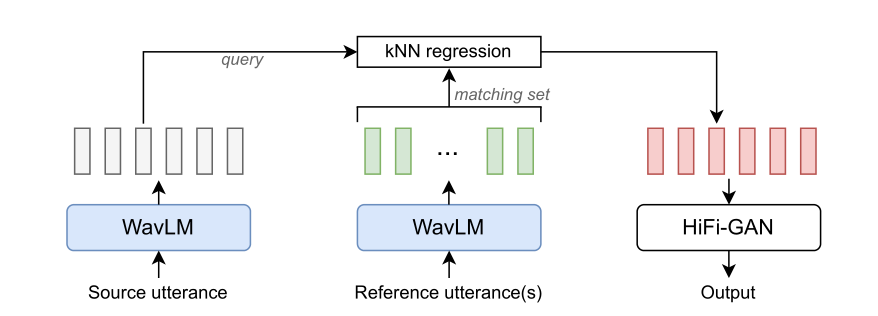
模型架构:源话语和参考话语被编码为来自预训练的WavLM模型的自监督特征[6]。每个源特征被分配给来自参考的k个最接近特征的平均值。然后使用HiFi GAN对得到的特征序列进行声码,以获得转换后的波形输出。
原理非常简单,不过个人怀疑需要的声音量可能是别的模型的几倍,由于是相当于直接利用embedding
对于我们所有的实验,我们用均匀的加权设置k=4,并使用余弦距离来比较特征。在初步实验中,我们发现kNN-VC在k=4左右的值范围内是相当稳健的。也就是说,当有更多的参考音频可用时(例如≥10分钟),甚至可以通过使用更大的k值(按k=20的顺序)来提高转换质量。
Voice Conversion With Just Nearest Neighbors
https://lijianxiong.space/2023/20230629/