chatgpt在数据集上的性能调查
简介:
chatgpt的流行及其各种令人印象深刻的功能使一些人相信它是在现有系统的语言能力上向前迈出的重要一步,nlp领域很快就会被生成语言模型所吞噬,甚至它预示着AGI。
为了验证这些说法,我对arXiv预打印进行了调查,将chatgpt与其他方法进行了比较,主要是使用较小的微调模型。
chatgpt的性能并不像我预期的那样令人印象深刻,因为它经常被更小的模型所超越。
方法论
截至2023-03-23,在arXiv上搜索chatgpt可以找到141篇论文。
为了过滤掉无关的论文,我忽略了那些似乎不是关于nlp研究的论文,或者那些讨论非性能方面的论文,比如chatgpt的政治倾向。
然后,我打开剩下的论文,滚动浏览它们,寻找一个可以在chatgpt和其他模型之间进行定量比较的表格或图表。
我找到了19篇符合这些标准的论文。这19篇论文的表格和图表在下面的附录中,并附有简要的评论。对于每篇论文,我统计了chatgpt比表现最好的非llm方法1获得更好分数的数据集的数量。如果一个数据集报告了多个分数,我会试着选择信息量最大的分数。如果报告了一个数据集的多个分割或变体,我试图找到信息量最大的子集。
结果
在151次比较中,Chatgpt赢得了34次(22.5%)。
在大多数经典的nlp任务中,chatgpt的性能并不优于现有的微调基线,尽管它通常很接近。
在某些情况下,它甚至无法击败简单的词袋模型(例如,预测Amin-Affective的亲和性- 58.5 vs 44.8的准确度),或者它比监督基线差得惊人的显著(例如,Bang-Benchmark中的clutrr关系推理数据集- 48.4 vs 23.3的准确度或kococo - benchmark中的goemotions情绪分类数据集- 52.75 vs 25.55的准确度)。
chatgpt与情感任务(kococo - benchmark, Amin-Affective)斗争,它有时比旧的bert-tier模型(Jang-Consistency)表现出更高的脆弱性。
我惊讶地发现chatgpt并不擅长文本生成任务,如总结或问题回答(wang - summary, Tan-QA),尽管人们非常喜欢这些功能。
chatgpt在语义相似性任务上似乎不是很强大,但它确实很擅长将生成的文本与引用进行比较(komic - evaluation, Wang-Evaluation)。
我认为这两种技能是高度相关的,但我想不是。
一些论文(Qin-Understanding, Wang-Robustness, Hendy-Translation)也对不同版本的gpt-3进行了比较。
结果好坏参半,我在任务中找不到chatgpt获胜或失败的任何模式。
这表明在训练过程中有一定程度的脆弱性,其中模型获得了一些能力,但它可能会失去其他能力,Ye等人2023。
当他们证明chatgpt在几个数据集和任务上比text-davinci-003更差时,就证实了这一点,令人惊讶的是,包括小队问答数据集。
说明
有几个重要的注意事项需要考虑。
我已经标记了每个说明是否表明chatgpt可能比报告的强(+)或弱(-)。
- Suboptimal utilization of chatgpt (+)
提示工程可以显著提高llm的表现(例如,在中理解中,78.7分vs 86.2分),但这里的一些论文只使用非常基本的提示技术。
很明显,一些chatgpt实验是在最后一分钟匆忙添加的。
随着未来人们对chatgpt和适当的提示技术越来越熟悉,性能利用率可能会提高,chatgpt可能会获得额外的胜利。
- Self-selected datasets (+).
研究人员倾向于设计数据集,这样它们就可以用现有的方法和途径来解决。
我相信,这就是为什么一些旧的分类数据集仍然具有单词袋方法的竞争性结果。
经过微调的模型可能会有很好的结果,因为数据集与它们的强项相匹配。
另一方面,由于缺乏适当的数据集或方法,许多有趣的chatgpt的能力目前难以衡量,因此它们没有包括在本次调查中。
- Data leakage (-)
完全有可能一些用于评估的数据集被泄露到chatgpt的训练集,这可能会影响结果。
一些数据集是公开可用的,在使用chatgpt期间可能发生了额外的泄漏。
实验gpt模型的研究人员通常会提供原始数据,如果他们使用较少的提示,甚至会提供标签。
目前还不清楚openai对这些数据做了什么,很可能对于许多数据集来说,chatgpt已经被污染了。
- Positive result bias (-).
当研究人员无法让chatgpt在他们特定的数据集或用例上工作时,他们可能不会报告。
- Weak baselines (-).
许多用于比较的基线不再是真正的sota模型。
对于chatgpt胜出的一些任务,您可能可以找到更好的模型。
- 主要是英语。
通常情况下,chatgpt的评估主要集中在英语语言上。众所周知,多语言评估缺乏适当的数据集。
结论
我对chatgpt的表现有点失望,也许这是不公平的。它没有达到宣传的效果,也没有达到我迄今为止看到的所有精选的例子。它仍然是一个伟大的多面手模型,它可以以某种方式执行许多技能,这是一个奇迹。但这距离真正的语言智能还很远。对于大多数经典的nlp任务来说,小型微调模型并不是那么令人印象深刻,这通常比这更糟糕。
我认为vanilla chatgpt将被用作一些应用程序的快速原型,但对于大多数生产就绪的解决方案,它将被一个经过微调的模型(出于经济原因,通常更小)所取代,除非需要自由文本交互。我还想知道他们将来是否会允许对gpt-3.5模型(包括chatgpt)进行微调。Openai(再次)提出了关于他们模型的安全问题,让人们对模型进行微调意味着他们违反了自己的安全措施。我想他们最终会这么做的,就像他们之前的所有模型一样。
很难预测新模型是否会明显优于chatgpt。在某种程度上,无论是计算方面还是数据方面,扩展范式都遇到了瓶颈。指数增长不可能无限期地持续下去,这一事实不应该那么令人惊讶。我们将不得不等待几个月的类似批次的论文来评估gpt-4,因为作者在他们的论文中除了回答问题之外没有报告任何内容。他们的api页面简单地说明:对于许多基本任务,gpt-4和gpt-3.5模型之间的差异并不显著。然而,在更复杂的推理情况下,gpt-4比我们之前的任何模型都更有能力。
这是否意味着扩展完全停止了对基本功能的改进,chatgpt基本上是性能的峰值?另一方面,复杂的推理可能是目前这些模型最有趣的特征,但不幸的是,在本次调查中,它几乎没有。
看起来gpt-3甚至更老的nlp模型通常具有类似的功能,但是chatgpt得到了所有媒体的关注。我想这说明了用户体验有多重要。人们不关心智能自动补全,因为他们需要摆弄一些模糊的参数,比如温度或top-p。但只要你把它包装成聊天工具,并赋予它一点个性,人们就会为之疯狂。我想知道 galactica的情况。如果他们不试图以科学界为目标,它可能会像chatgpt一样成功——在科学界,事实性(llms的一个众所周知的弱点)是最重要的价值观之一。
评估llms正变得越来越困难。gpt模型的作者只报告了少数数据集上的结果,社区需要以不协调的方式测试其余的数据集。数据泄露对评估的有效性是一个持续的威胁,我们可能不得不从头开始重新思考。我可以预见用户研究在未来会被更多地使用,但那将会更加昂贵。Big-bench是一个由442名志愿研究人员共同撰写的大型基准集合,旨在测试llms,由于数据泄漏,对于最受欢迎的llms之一来说,它几乎完全无用。学术界花费数千小时或美元来测试(阅读,为模型所有者提供价值)完全封闭的模型,这有点病态,这些模型可以随时被删除、更新或污染,(我在这里的工作与此类似。讽刺的是,我也知道)。
附录
Bang-Benchmark
Bang, Y., Cahyawijaya, S., Lee, N., Dai, W., Su, D., Wilie, B., … & Fung, P. (2023). A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. arXiv preprint arXiv:2302.04023.
3 out of 21. This is the most thorough paper in this survey. They compared chatgpt with fine-tuned and zero-shot sota on 21 datasets from 7 tasks: summarization, machine translation, sentiment analysis, question answering, misinformation detection, task-oriented dialogue, and open-domain knowledge-grounded dialogue. chatgpt was able to win only in a small handful of cases. Additionally, they evaluated chatgpt’s multilinguality, multimodality, reasoning capabilities, factuality, and interactivity, but that’s outside of my scope here. There is not much information about their prompt design, and they did not report confidence intervals for the scores, despite calculating them only from a small test sets (mostly 50 samples). Small samples size is actually a problem for many of the papers here, probably because of the limited API access people had.
I am skeptical about the covid-scientific dataset, which they describe as a testset that consists of covid-19-related scientific or medical myths that must be debunked correctly to ensure the safety of the public. In my experience, it appears that chatgpt was heavily reinforced to align its communication regarding covid-19 in a particular manner and was likely exposed to significant amounts of texts about covid-19 misinformation. The excellent performance on this dataset may be the result of what is essentially a data leak.
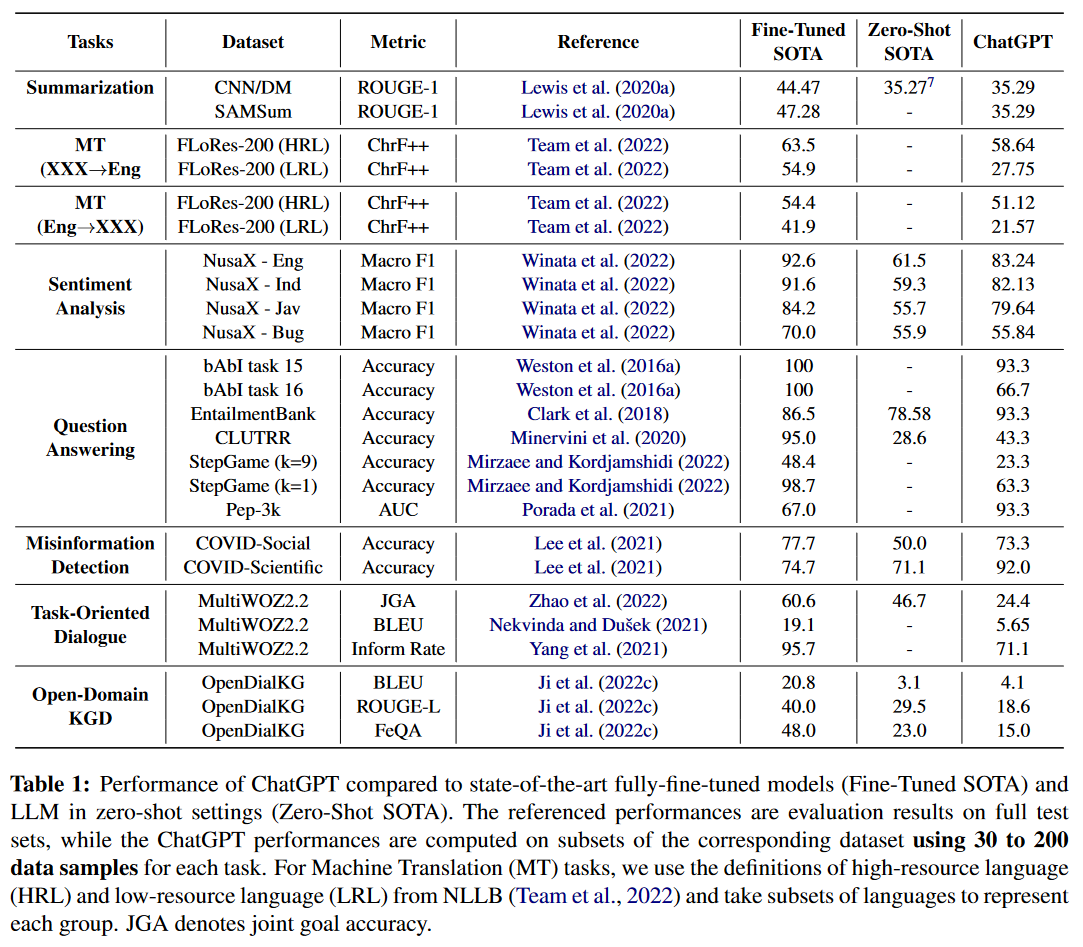
Kocoń-Benchmark
Kocoń, J., Cichecki, I., Kaszyca, O., Kochanek, M., Szydło, D., Baran, J., … & Kazienko, P. (2023). ChatGPT: Jack of All Trades, Master of None. arXiv preprint arXiv:2302.10724.
0 out of 25. This benchmarking paper analyzes chatgpt’s performance on 25 datasets from 11 tasks: offensiveness detection, linguistic acceptability, humor recognition, spam detection, word sense disambiguation, natural language inference, question answering, emotion recognition, sentiment analysis, emoji prediction, and stance detection. Some of these tasks are in Polish. chatgpt performed worse in all tasks, often by a significant margin. It particularly struggled with emotion and pragmatic tasks. They used few-shot prompting in some cases (aggressionper and goemoper datasets), while other tasks only had vanilla prompting.
They calculated some interesting correlations regarding the performance metrics. First, Figure 7 in their paper shows that chatgpt seems to perform worse for more difficult tasks — tasks where sota is further away from 100% performance. This may suggest that chatgpt struggles with long-tail tasks. Second, they estimated the probability of data leaking to chatgpt for each dataset. Most datasets were marked as either probable or highly probable, which is alarming in its own right. Figure 10 shows that datasets with a lower leak probability had worse performance, suggesting that data leak might have inflated the results in some cases. However, I would like to see this without the goemoper tasks, where chatgpt was asked to imitate specific annotators based on 1-3 examples of their annotations. chatgpt performed 30-47% worse than sota on these tasks, and it might have skewed the results.
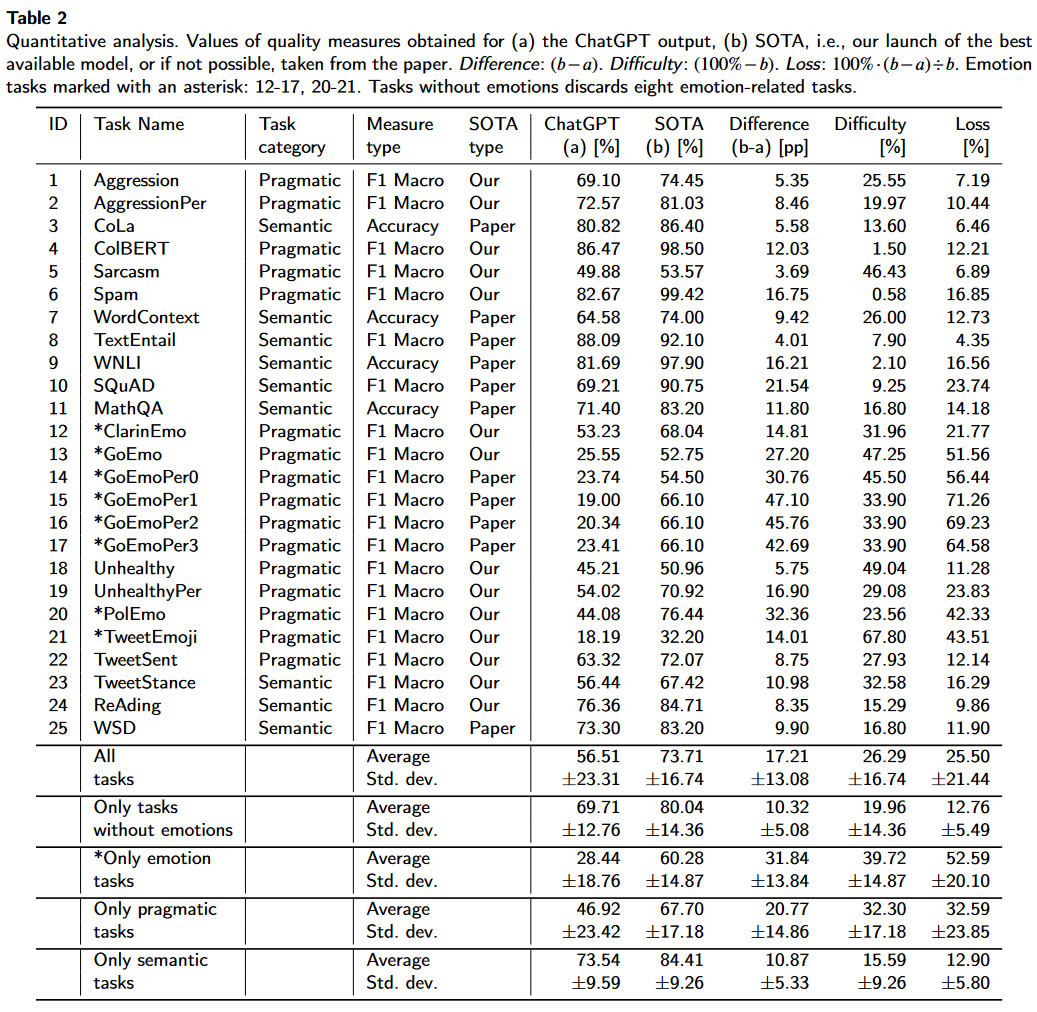
Qin-Understanding
Qin, C., Zhang, A., Zhang, Z., Chen, J., Yasunaga, M., & Yang, D. (2023). Is ChatGPT a General-Purpose Natural Language Processing Task Solver? arXiv preprint arXiv:2302.06476.
0 out of 7. This is another paper that compares chatgpt’s performance across a significant number of tasks. Figure 1 is actually misleading since the Fine-tuning models for all the Reasoning tasks (the first two rows of results) are also just language models prompted with chain-of-thought few-shot prompts. Therefore, I only consider the results from the last row where fine-tuned models are actually used. They outperform chatgpt in all cases.
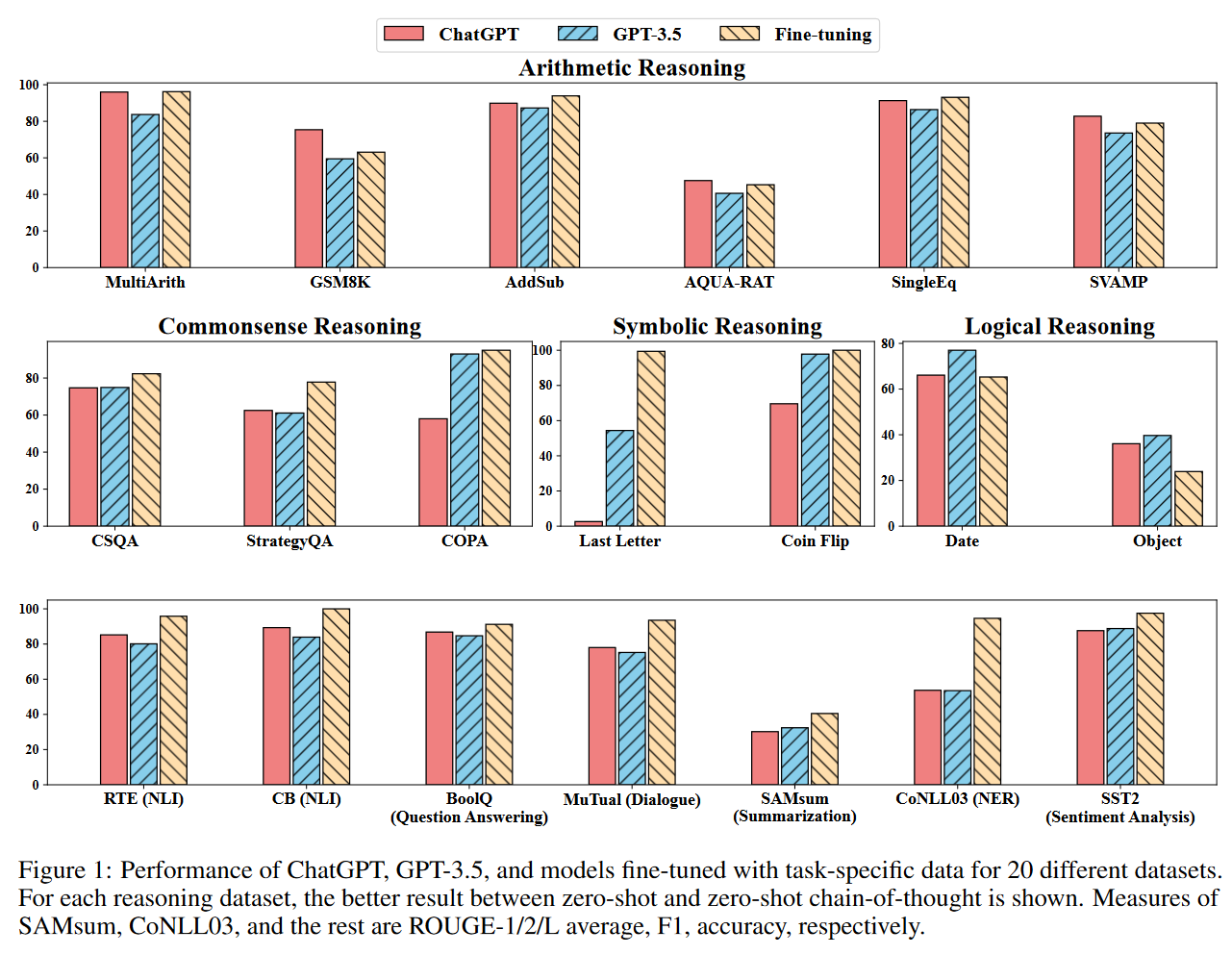
Zhong-Understanding
Zhong, Q., Ding, L., Liu, J., Du, B., & Tao, D. (2023). Can ChatGPT Understand Too? A Comparative Study on ChatGPT and Fine-tuned BERT. arXiv preprint arXiv:2302.10198.
1 out of 8. This is a comparison on the glue natural language understanding benchmark. They actually use some of the more advanced prompting strategies, including few-shot and chain-of-thought prompts. Their basic prompts were generated by chatgpt, a bizzare decision, as I doubt that chatgpt is self-conscious enough that it’s able to generate optimal prompts for itself. The prompting techniques helped to improve the average performance from 78.7 to 86.2.
chatgpt arguably outperformed the roberta-large model in 4 out of the 8 tasks reported here. However, in this case, I have decided to compare the performance with the glue leaderboard instead, as roberta is a bit outdated by now. Compared to the true sota results (turing ulr v6 model), chatgpt performed better only for sentiment analysis. chatgpt did not perform particularly well for sentiment analysis in the three previous papers, but they all used only vanilla prompts. The authors also discuss the instability of few-shot prompting. The performance for the cola dataset can differ by more than 20% depending on the selected examples.

Jang-Consistency
Jang, M., & Lukasiewicz, T. (2023). Consistency Analysis of ChatGPT. arXiv preprint arXiv:2303.06273.
3 out of 9. The authors show that chatgpt is surprisingly brittle when the input texts are perturbed, in some cases even more so than bert-tier models. They tested two text comparison tasks (paraphrase detection and natural language inference) with three types of perturbations:
- Semantic perturbations. How do the predictions change if we paraphrase one of the inputs? The paraphrases were generated by quilbot or chatgpt. chatgpt changes its prediction 10-30% of the time if we rephrase one of the inputs. It\s more consistent for paraphrases generated by itself.
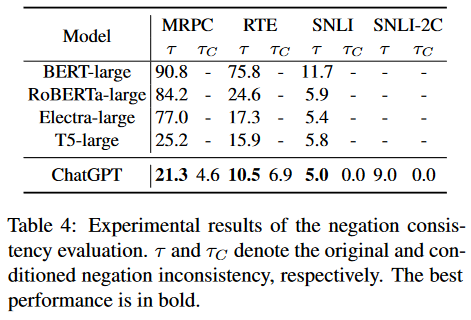
- Negation perturbations. How do the predictions change if we negate the input? chatgpt performs better than older models, which are notorious for not understanding negation Kassner & Schütze 2020 . In this case, we expect negation to flip the prediction.
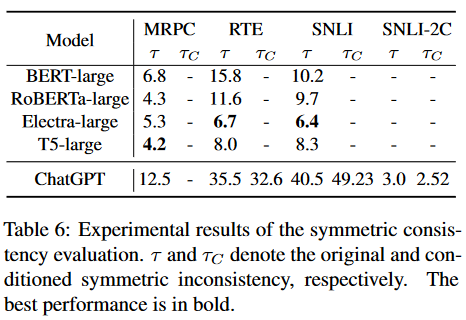
- Symmetric perturbations. How do the predictions change if we switch the order of the inputs? chatgpt is incredibly inconsistent in this regard, much more so than any of the older models. mrpc is a completely symmetric task (do the two sentences have the same meaning?), but chatgpt changes its prediction based on the order of the two sentences in 12.5% of cases. To improve the results, they had to merge neutral and contradiction labels into one in snli-2c. The fact that the model cannot distinguish between these two concepts is also concerning.

Wang-Robustness
Wang, J., Hu, X., Hou, W., Chen, H., Zheng, R., Wang, Y., … & Xie, X. (2023). On the Robustness of ChatGPT: An Adversarial and Out-of-Distribution Perspective. arXiv preprint arXiv:2302.12095.
8 out of 8. The brittleness (or robustness) is the main topic of this paper as well. They test two scenarios: (1) adversarial attacks and (2) out-of-domain generalization. chatgpt is the clean winner as it was able to achieve the best results in all cases. I specifically checked for possible data leaks for the adversarial datasets in this case, as this is the paper where chatgpt has the best win ratio. There are a handful of samples leaked on the advglue benchmark website, but the biggest leak is probably HuggingFace Datasets page where they show 100 samples for each of the subsets tested here. Some of them are quite small (e.g., rte has only 302 samples) and a large portion of the datasets could have been leaked this way. Otherwise, I don’t understand how chatgpt became so much better than text-davinci-003 in some cases .

Wang-Summarization
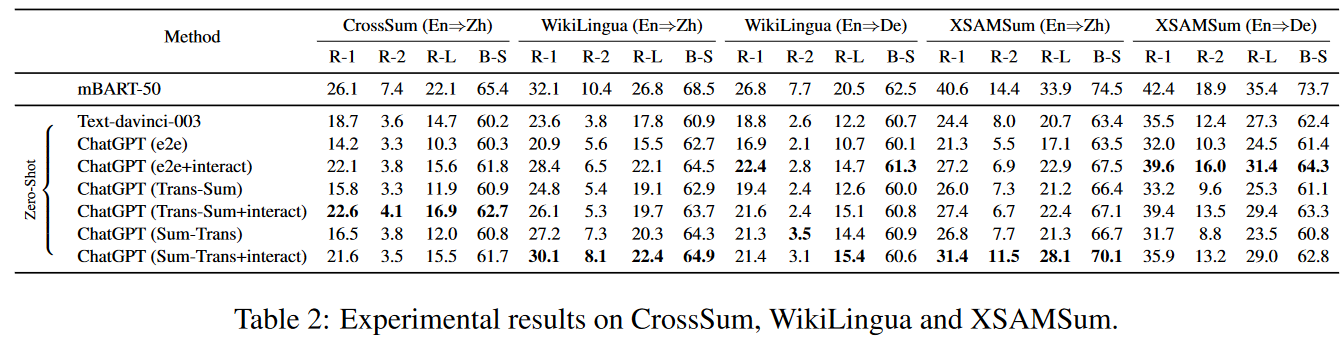
Wang, J., Liang, Y., Meng, F., Li, Z., Qu, J., & Zhou, J. (2023). Cross-Lingual Summarization via ChatGPT. arXiv preprint arXiv:2302.14229.
0 out of 5. Qin-Understanding and Bang-Benchmark have already shown that chatgpt does not beat the sota models for English summarization. Here, the authors show the same for crosslingual summarization (English to Mandarin and English to German). It could be argued that the evaluation metrics (mainly rouge) do not match the use case perfectly, and a user study should be conducted to see how people react to the outputs. On the other hand, Bang-Benchmark claim that the summaries produced by chatgpt are sometimes longer than the input documents, so it’s hard to believe that chatgpt really gets what this task is about.
Yang-Summarization
Yang, X., Li, Y., Zhang, X., Chen, H., & Cheng, W. (2023). Exploring the Limits of ChatGPT for Query or Aspect-Based Text Summarization. arXiv preprint arXiv:2302.08081.
2 out of 6. chatgpt was actually able to achieve some summarization wins here, although the tasks are query-based and aspect-based summarization. Perhaps these tasks are better aligned with chatgpt’s training. It wins an aspect-based newts dataset and is also competitive for qmsum, where the task is to summarize a meeting transcript according to a specific query. The golden version only includes the parts of the meeting that are relevant to the input query.

Hendy-Translation
Hendy, A., Abdelrehim, M., Sharaf, A., Raunak, V., Gabr, M., Matsushita, H., … & Awadalla, H. H. (2023). How Good are GPT Models at Machine Translation? A Comprehensive Evaluation. arXiv preprint arXiv:2302.09210.
1 out of 8. This paper is a pretty robust evaluation of the machine translation capabilities of the gpt models. The one experiment that uses chatgpt is shown in the Figure below. The best performing models from the wmt benchmark outperformed the gpt models for most metrics. The comparison between text-davinci-003 and chatgpt is less clear and depends on the language. There are other experiments in the paper, but they do not use chatgpt. The paper is actually exceptionally in-depth, and the follow-up investigation paints a much better picture of the capabilities of gpt models than the basic table shown here.
![]()
Jiao-Translation
Jiao, W., Wang, W., Huang, J. T., Wang, X., & Tu, Z. (2023). Is ChatGPT a Good Translator? A Preliminary Study. arXiv preprint arXiv:2301.08745.
1 out of 16. This is another, in my opinion, weaker, machine translation paper. chatgpt falls behind the available machine translation systems in almost all cases, except for one dataset, wmt20 rob3 — an out-of-distribution test set based on transcribed speech. This is another paper that made the bizarre decision to ask chatgpt for the prompts.
![]()
![]()
Kocmi-Evaluation
Kocmi, T., & Federmann, C. (2023). Large Language Models are State-of-the-Art Evaluators of Translation Quality. arXiv preprint arXiv:2302.14520.
1 out of 1. This paper has found that chatgpt is an excellent evaluator of translations. gpt models have outperformed existing measures and models in terms of their alignment with human judgements. The performance of individual gpt models depends on the prompt formulation. text-davinci-003 works best with a 0-100 scale, text-davinci-002 when it has to select 1-5 stars, and chatgpt when it has to select from five text descriptions (e.g., No meaning preserved or Some meaning preserved, but not understandable).

Wang-Evaluation
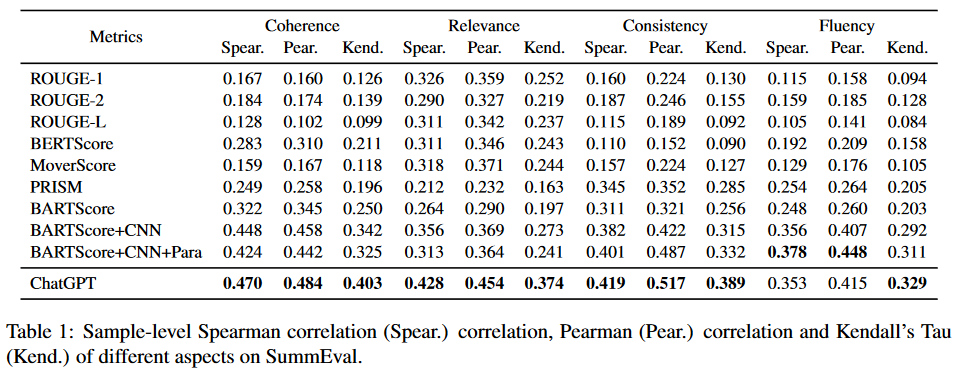
Wang, J., Liang, Y., Meng, F., Shi, H., Li, Z., Xu, J., … & Zhou, J. (2023). Is ChatGPT a Good NLG Evaluator? A Preliminary Study. arXiv preprint arXiv:2303.04048.
2 out of 3. This paper confirms the results from Kocmi-Evaluation and shows that chatgpt is great for text evaluation. Instead of machine translation, they use summarization (summeval), story generation (openmeva), and data-to-text (bagel) tasks.


Tan-QA
Tan, Y., Min, D., Li, Y., Li, W., Hu, N., Chen, Y., & Qi, G. (2023). Evaluation of ChatGPT as a Question Answering System for Answering Complex Questions. arXiv preprint arXiv:2303.07992.
2 out of 8. The authors evaluated chatgpt’s performance on 8 question answering datasets, including two multilingual ones. The results showed that chatgpt’s performance varied significantly. It outperformed the sota model by a significant margin for wqsp, but fell completely behind for qald-9. This unpredictability is not surprising, as question answering depends on two factors: (1) the number of answers in the training data, and (2) the number of answers the model memorized. These factors can vary significantly for questions from different domains or languages. The authors also observed that chatgpt is less stable for similar/nearly identical inputs (see also Jang-Consistency).

Omar-QA
Omar, R., Mangukiya, O., Kalnis, P., & Mansour, E. (2023). ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots. arXiv preprint arXiv:2302.06466.
1 out of 4. This is another paper that evaluates question answering, but they focus on knowledge graphs. chatgpt performs reasonably well on the general knowledge datasets (yago and qald-9), but it fails completely on the academic datasets (dblp and mag). These academic datasets have questions about the virtual academic knowledge graph of authors, publications, and citations. Theoretically, chatgpt has seen most of this graph during the training, but it’s obviously unable to infer this level of information from the raw text data. Compared to Tan-QA, the non-gpt baselines used here are actually quite weak (the sota models have f1 in 80s for the qald-9).

Wei-Extraction
Wei, X., Cui, X., Cheng, N., Wang, X., Zhang, X., Huang, S., … & Han, W. (2023). Zero-Shot Information Extraction via Chatting with ChatGPT. arXiv preprint arXiv:2302.10205.
2 out of 6. This paper evaluates three information extraction tasks: entity-relation triple extraction (re), named entity recognition (ner), even extraction (ee). They report the results for Mandarin and English, with the first dataset for all three tasks in the table below being Mandarin. They compared fine-tuning smaller models (full-shot for normal fine-tuning or fs-x for few-shot tuning) with vanilla chatgpt prompting (single), and a more complex multi-turn chatgpt dialogue (chatie). Don’t get fooled by the bolded results. The fine-tuned baselines are mostly better. chatgpt performed poorly for ner but was able to outperform full-shot solutions for Mandarin re and ee.

Gao-Extraction
Gao, J., Zhao, H., Yu, C., & Xu, R. (2023). Exploring the Feasibility of ChatGPT for Event Extraction. arXiv preprint arXiv:2303.03836.
0 out of 1. This paper evaluates event extraction on the ace dataset. The results are calculated only from a handful of samples (20 for each category), there are no confidence intervals, and the f1 score for chatgpt Simple Examples does not make sense given the Precision and Recall values. The authors split the samples based on the event frequency (how many times that event is mentioned in the training dataset) and the sample complexity (how many events are in one sample), but the results are all over the place, likely due to the small size of the test sets.

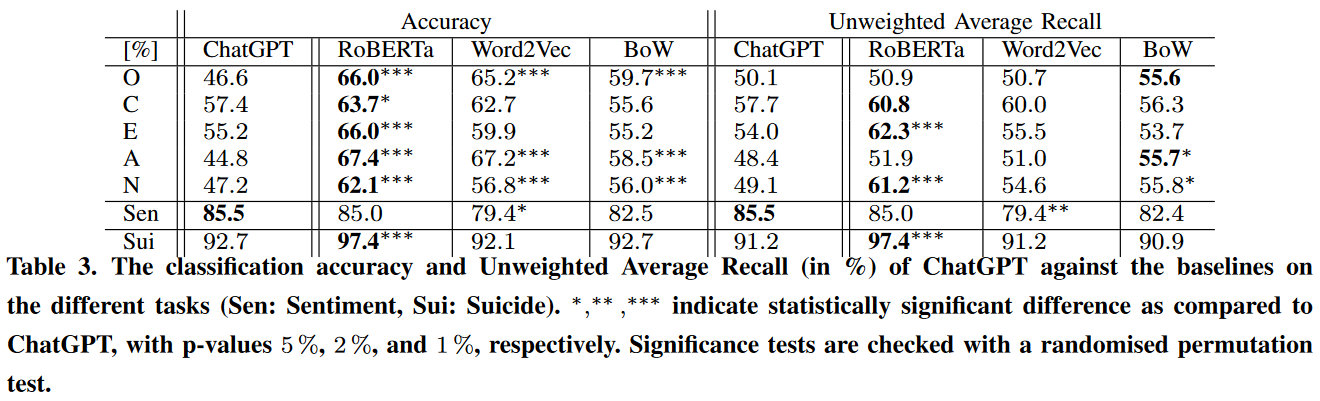
Amin-Affective
Amin, M. M., Cambria, E., & Schuller, B. W. (2023). Will Affective Computing Emerge from Foundation Models and General AI? A First Evaluation on ChatGPT. arXiv preprint arXiv:2303.03186.
1 out of 7. A very straightforward comparison between chatgpt and a set of rather simple baselines for three affective classification tasks: big-five personality prediction, sentiment analysis, and suicide tendency detection. chatgpt’s results are really not impressive and it managed to win only sentiment analysis. In some cases, it was beaten even by a bag-of-words approach. Note that Kocoń-Benchmark also claim that chatgpt does not work well on emotional tasks. chatgpt managed to win sentiment analysis in this paper and in Zhong-Understanding, but in both cases it was only compared to roberta. When it’s compared with the sota models, it falls behind (Bang-Benchmark, Kocoń-Benchmark, Qin-Understanding).
Kuzman-Genre
Kuzman, T., Mozetič, I., & Ljubešić, N. (2023). ChatGPT: Beginning of an End of Manual Linguistic Data Annotation? Use Case of Automatic Genre Identification. arXiv preprint arXiv:2303.03953.
1 out of 2. A very straight-forward paper where they compare chatgpt with an xlm-roberta based fine-tuned model for genre classification. They use English (en-ginco) and Slovenian (ginco) datasets. chatgpt performed better on the English one.

Zhang-Stance
Zhang, B., Ding, D., & Jing, L. (2022). How would Stance Detection Techniques Evolve after the Launch of ChatGPT?. arXiv preprint arXiv:2212.14548.
5 out of 6. They evaluate the performance on stance detection, which is a task that aims to identify whether a text is in favor of or against something. They used two datasets, the first of which contains texts about the feminist movement (fm), the legalization of abortion (la), and Hillary Clinton (hc). The second dataset is about us politicians. chatgpt outperformed sota in 5 out of 6 splits, with the only exception being the abortion split.