yolo三剑客
yolo=you only look once
一个非常常用的目标检测算法
现在有5个版本,前三个由yolo之父Joseph Redmon领衔的研究人员研发。yolov3提出后不久,Joseph Redmon宣布退出CV界。故后两个版本均有另外的人研发。
yolov1
优缺点
优点:
1.速度快,性能优于其他检测方法,包括DPM和R-CNN。
YOLO在训练和测试期间看到整个图像,因此它隐式地编码有关类及其外观的上下文信息。Fast R-CNN是一种顶级检测方法,它会将图像中的背景补丁误认为是物体,因为它看不到更大的背景。与Fast R-CNN相比,YOLO犯的背景错误不到一半。
缺点:
精确度不高,虽然它可以快速识别图像中的物体,但它很难精确定位某些物体,尤其是小物体。
由于模型从数据中学习预测边界框,因此很难将其推广到具有新的或不寻常的长宽比或配置的对象
算法流程
算法将输入图像划分为S×S网格。如果物体的中心落入网格单元,该网格单元负责检测该物体。每个网格单元预测B个边界框和这些框的置信度分数。这些置信度分数反映了模型对盒子包含对象的置信度,以及它认为盒子预测的准确性。
在形式上,我们将置信度定义为
$$
Pr(物体)*IOU^{truth}_{pred}
$$
每个边界框由5个预测组成:x、y、w、h和置信度。
x,y坐标是预测框的中心坐标。w、h是预测框的宽度和高度。最后,置信度预测表示预测框和任何实际框之间的IOU。每个网格单元还预测C条件类概率$Pr(Class_i | Object)$。这些概率取决于包含对象的网格单元。
网络结构
网络结构基于 GoogLeNet。
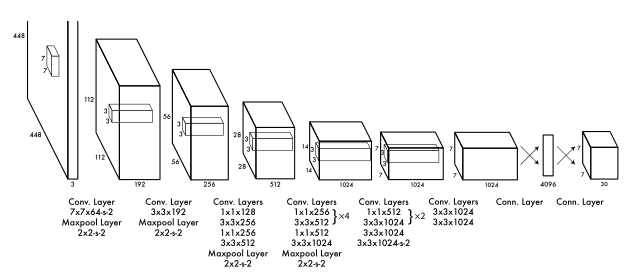
Fast YOLO使用的神经网络具有较少的卷积层(9层而不是24层)和较少的滤filter。除了网络的大小之外,YOLO和Fast YOLO之间的所有训练和测试参数都是相同的。
为了避免过拟合,使用了Dropout 和数据增强(原始图像20%的随机缩放和旋转、在HSV上将曝光度和饱和度乘以若干不高于1.5的倍数)
与其他目标检测算法的对比
yolov2
又叫yolo9000,因为可以对9000个类别识别。
改进之处
增加了BN层
增加了分辨率
使用了anchor
使用Kmeans选择anchor
anchor的思想来自于Fast-RCNN。anchor是从数据集中统计得到的(Faster-RCNN中的Anchor的宽高和大小是手动挑选的)。
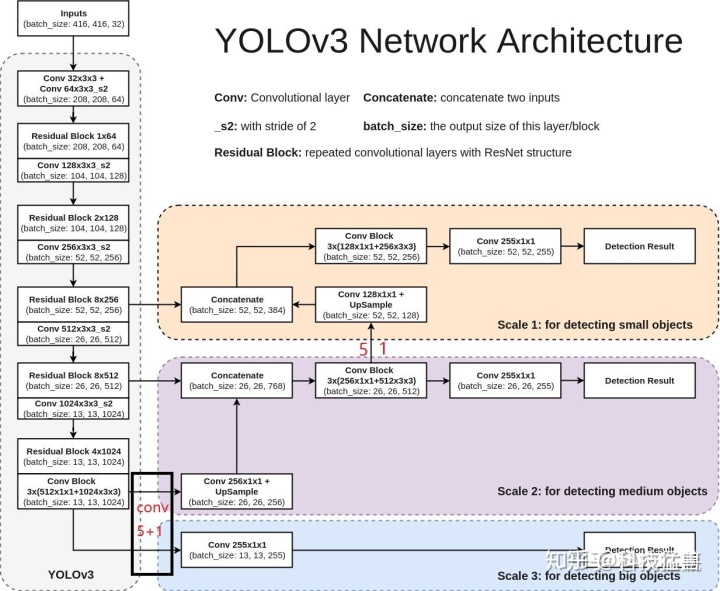
yolov3
改进之处
网络结构发生变化
softmax->交叉熵:
YOLO v3使用多标签分类,用多个独立的logistic分类器代替softmax函数,以计算输入属于特定标签的可能性。在计算分类损失进行训练时,YOLO v3对每个标签使用二元交叉熵损失。