ResNet
论文:何恺明等 - Deep Residual Learning for Image Recognition
更深的网络可能面临误差变高的问题,但并不是过拟合(过拟合是训练误差变低,但测试误差变高,而更深的网络面临的问题是训练误差也变低。)
本文提出了一种框架(deep residual learning framework)来避免浅层神经网络到深度神经网络出现的这种情况。
要学的东西叫做H(x),假设现在已经有了一个浅的神经网络,他的输出是x,然后要在这个浅的神经网络上面再新加一些层,让它变得更深。新加的那些层不要直接去学H(x),而是应该去学H(x)-x,x是原始的浅层神经网络已经学到的一些东西,新加的层不要重新去学习,而是去学习学到的东西和真实的东西之间的残差,最后整个神经网络的输出等价于浅层神经网络的输出x和新加的神经网络学习残差的输出之和,将优化目标从H(x)转变成为了$F(x)=H(x)-x $
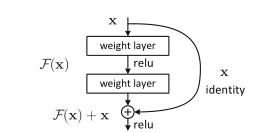
残差使用了Shortcut Connection等先人的技术。
应用:
残差连接如何处理输入和输出的形状是不同的情况:
第一个方案是在输入和输出上分别添加一些额外的0,使得这两个形状能够对应起来然后可以相加
第二个方案是之前提到过的全连接怎么做投影,做到卷积上,是通过一个叫做11的卷积层,这个卷积层的特点是在空间维度上不做任何东西,主要是在通道维度上做改变。所以只要选取一个11的卷积使得输出通道是输入通道的两倍,这样就能将残差连接的输入和输出进行对比了。在ResNet中,如果把输出通道数翻了两倍,那么输入的高和宽通常都会被减半,所以在做1*1的卷积的时候,同样也会使步幅为2,这样的话使得高宽和通道上都能够匹配上
图像处理:
短边随机裁剪到[256,480]。pre-pixel取均值。增强图像。
神经网络使用引用论文[13](其实就是作者之前自己写的)的权重。
minibatch=256,学习率0.1,当错误率不显著下降时每次除10。
训练了$60 *10^4$代。
没有使用dropout,因为没有全连接层。
测试的时候,使用了10-crop testing(就是给定一张测试图片,会在里面随机的或者是按照一定规则的去采样10个图片出来,然后再每个子图上面做预测,最后将结果做平均)。这样的好处是因为训练的时候每次是随机把图片拿出来,测试的时候也大概进行模拟这个过程,另外做10次预测能够降低方差。
在不同的分辨率上去做采样,工作量较大,一般不这么做。
实验:
神经网络架构。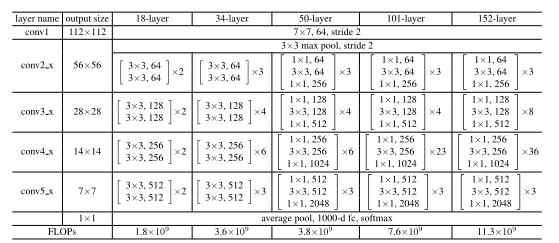
结果图:
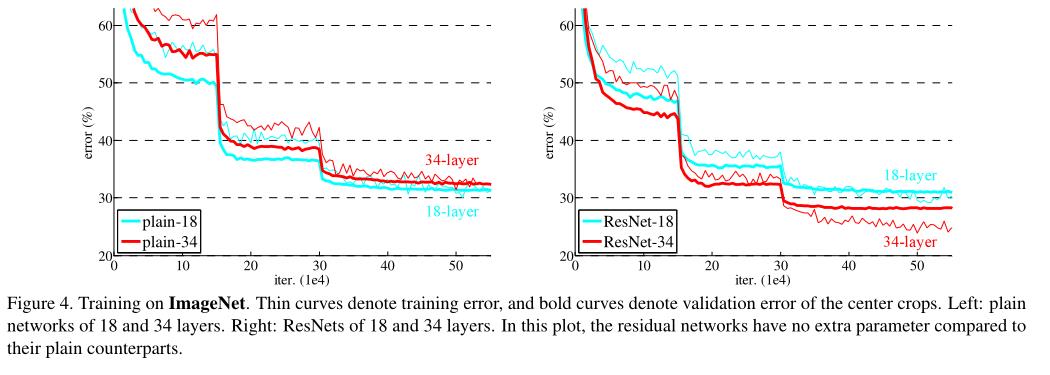
图中的误差急剧下降是因为学习率*0.1。
输入输出形状不一样的时候怎样做残差连接:
A:填零
B:投影
C:所有的连接都做投影:就算输入输出的形状是一样的,一样可以在连接的时候做个1*1的卷积,但是输入和输出通道数是一样的,做一次投影
B和C虽然差不多,但是计算复杂度更高,B对计算量的增加比较少,作者采用了B
bottleneck 设计:
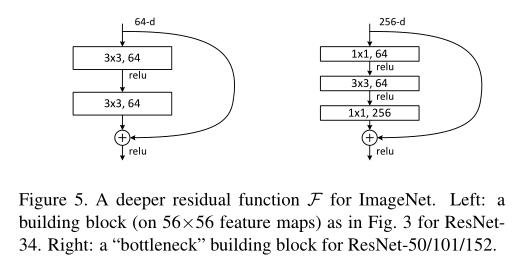
为什么好:
与没加残差相比,梯度能保证够大,保证能训练。
设浅层神经网络为$g(x)$,则深层神经网络可以看成f(g(x))
求导$\frac{\partial f(g(x))}{\partial x}=\frac{\partial f(g(x))}{\partial g(x))} \frac{\partial g(x)}{\partial x}$
残差:$\frac{\partial (f(g(x))+g(x))}{\partial g(x))}=\frac{\partial f(g(x))}{\partial g(x))} \frac{\partial g(x)}{\partial x}+\frac{\partial g(x)}{\partial x}$
另外:
这篇文章的residual和gradient boosting是不一样的
- gradient boosting是在标号上做residual
- 这篇文章是在feature维度上