机器学习之建议与应用
机器学习的建议
面对模型的下一步操作:
我们可以
获得更多的训练样本——通常是有效的,但代价较大,下面的方法也可能有效,可考虑先采用下面的几种方法。
尝试减少特征的数量
尝试获得更多的特征
尝试增加多项式特征
尝试减少正则化程度$\lambda$
尝试增加正则化程度$\lambda$
我们该怎么选择呢?我们应该运用一些方法——被称为”机器学习诊断法”——来帮助我们知道上面哪些方法对我们的算法是有效的。
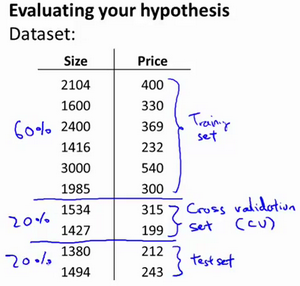
训练集与测试集
为了检验算法是否过拟合,我们将数据分成训练集和测试集,通常用70%的数据作为训练集,用剩下30%的数据作为测试集。
测试集评估在通过训练集让我们的模型学习得出其参数后,对测试集运用该模型。
模型选择
假设我们要在10个不同次数的二项式模型之间进行选择:
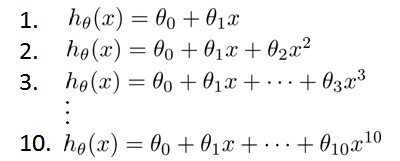
我们需要使用交叉验证集来帮助选择模型。 即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集。
模型选择的方法为:
使用训练集训练出10个模型
用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
选取代价函数值最小的模型
用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)
Train/validation/test error
Training error:
$J _{train}(\theta)=\frac{1}{2m}\sum _\limits{i=1}^{m}(h _{\theta}(x^{(i)})-y^{(i)})^2$
Cross Validation error:
$J _{cv}(\theta)=\frac{1}{2m _{cv}}\sum _\limits{i=1}^{m}(h _{\theta}(x^{(i)} _{cv})-y^{(i)} _{cv})^2$
Test error:
$J _{test}(\theta)=\frac{1}{2m _{test}}\sum _\limits{i=1}^{m _{test}}(h _{\theta}(x^{(i)} _{cv})-y^{(i)} _{cv})^2$
偏差与方差
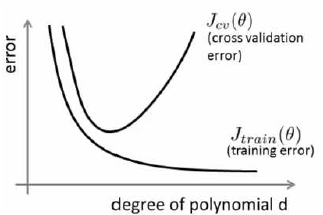
Bias/variance
Training error: $J_{train}(\theta) = \frac{1}{2m}\sum_\limits{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^2$
Cross Validation error:
$J _{cv}(\theta) = \frac{1}{2m _{cv}}\sum _\limits{i=1}^{m}(h _{\theta}(x^{(i)} _{cv})-y^{(i)} _{cv})^2$
我们如何判断是方差还是偏差呢?根据上面的图表,我们知道:
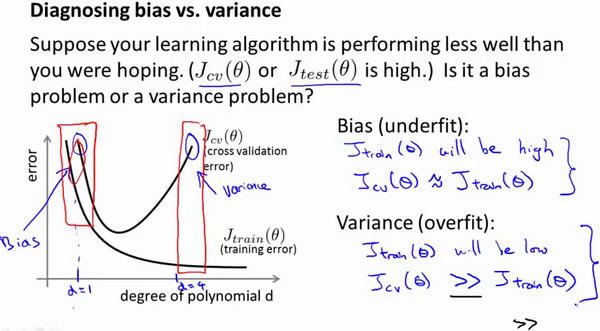
训练集误差和交叉验证集误差近似时:偏差/欠拟合 交叉验证集误差远大于训练集误差时:方差/过拟合
正则化系数的选择
我们选择一系列的想要测试的 $\lambda$ 值,通常是 0-10之间的呈现2倍关系的值(如:$0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10$共12个)。 我们同样把数据分为训练集、交叉验证集和测试集。

- 用训练集训练出12个不同程度正则化的模型
- 用12个模型分别对交叉验证集计算的出交叉验证误差
- 选择得出交叉验证误差最小的模型
- 运用步骤3中选出模型对测试集计算得出推广误差,我们也可以同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:

• 当 $\lambda$ 较小时,训练集误差较小(过拟合)而交叉验证集误差较大
• 随着 $\lambda$ 的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加
学习曲线
学习曲线是将训练集误差和交叉验证集误差作为训练集样本数量($m$)的函数绘制的图表。
即,如果我们有100行数据,我们从1行数据开始,逐渐学习更多行的数据。思想是:当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据。
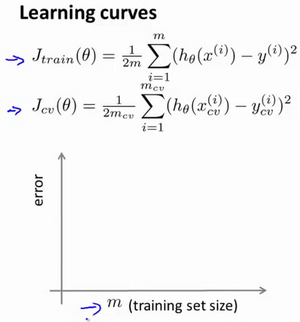
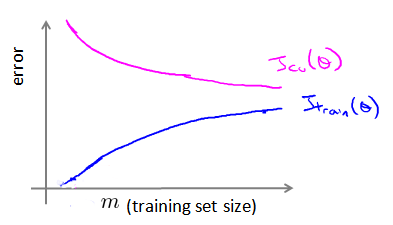
(一)如何利用学习曲线识别高偏差/欠拟合:
作为例子,我们尝试用一条直线来适应下面的数据,可以看出,无论训练集有多么大误差都不会有太大改观:
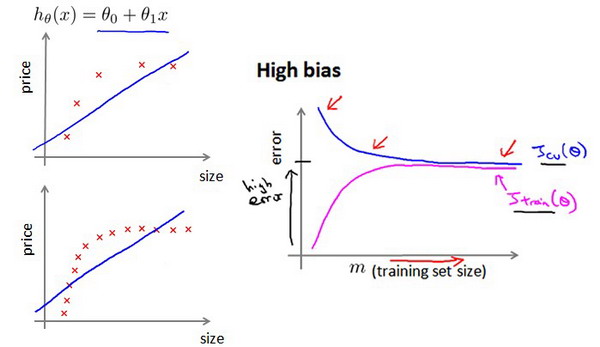
也就是说在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。
(二)如何利用学习曲线识别高方差/过拟合:
假设我们使用一个非常高次的多项式模型,并且正则化非常小,可以看出,当交叉验证集误差远大于训练集误差时,往训练集增加更多数据可以提高模型的效果。
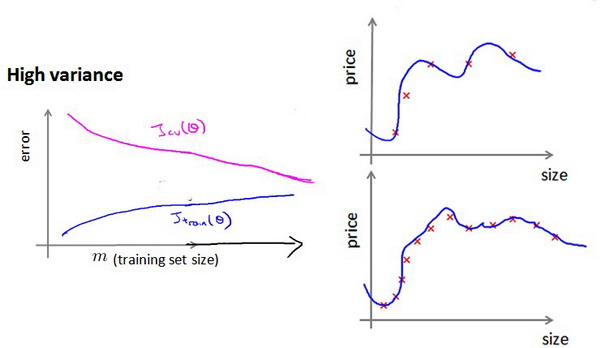
也就是说在高方差/过拟合的情况下,增加更多数据到训练集可能可以提高算法效果
选择下一步
回顾前面中提出的六种可选的下一步,让我们来看一看我们在什么情况下应该怎样选择:
- 获得更多的训练样本——解决高方差
- 尝试减少特征的数量——解决高方差
- 尝试获得更多的特征——解决高偏差
- 尝试增加多项式特征——解决高偏差
- 尝试减少正则化程度λ——解决高偏差
- 尝试增加正则化程度λ——解决高方差
误差分析(Error Analysis)
即人工检查交叉验证集中我们算法中产生预测误差的样本,看看这些样本是否有某种系统化的趋势。
比如当我们在构造垃圾邮件分类器时,我会看一看我的交叉验证数据集,然后亲自看一看哪些邮件被算法错误地分类。因此,通过这些被算法错误分类的垃圾邮件与非垃圾邮件,你可以发现某些系统性的规律:什么类型的邮件总是被错误分类。经常地这样做之后,这个过程能启发你构造新的特征变量,或者告诉你:现在这个系统的短处,然后启发你如何去提高它。
类偏斜的误差度量
训练集中有非常多同一类的样本,只有很少或者没有其他类的样本,这样的训练样本称为偏斜类。(skewed classes)
比如预测癌症是否恶性的 100 个样本中:95 个是良性的肿瘤,5 个恶性的肿瘤,假设我们在这个样本上对比以下 2 种分类算法的百分比准确度,即分类错误的百分比:人为把所有的样本都预测为良性,则分错了 5 个恶性的样本,错误率为 5 / 100 = 0.05 = 5%
如果仅仅从错误率大小来判断算法的优劣是不合适的,
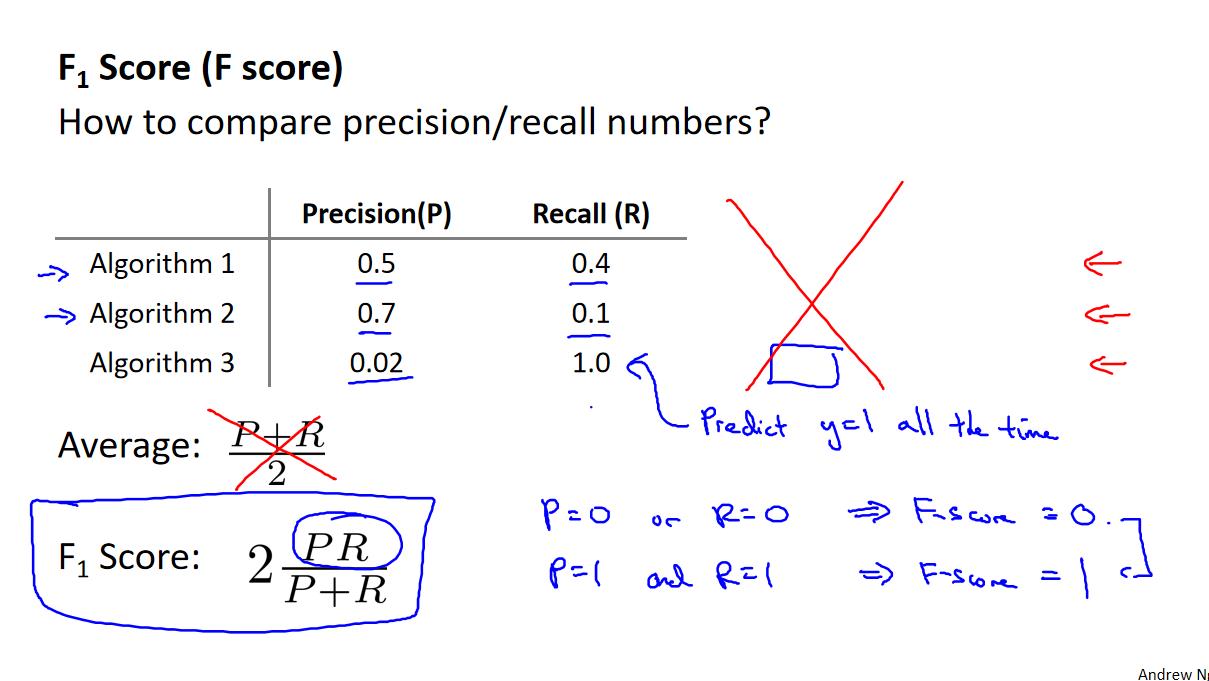
为了解决这个问题,使用**查准率(Precision)和查全率(Recall)**这 2 个误差指标,为了计算这 2 者,我们需要把算法预测的结果分为以下 4 种:
- 真阳性(True Positive,TP):预测为真,实际为真
- 真阴性(True Negative,TN):预测为假,实际为假
- 假阳性(False Positive,FP):预测为真,实际为假
- 假阴性(False Negative,FN):预测为假,实际为真
则:
查准率=TP/(TP+FP)。例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,查准率越高越好。
查全率=TP/(TP+FN)。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比。查全率越高越好。
这样,对于我们刚才那个总是预测病人肿瘤为良性的算法,其查全率是0。
| 预测值 | |||
|---|---|---|---|
| Positive | Negtive | ||
| 实际值 | Positive | TP | FN |
| Negtive | FP | TN |
均衡查准率和查全率
高查准率意味着只在非常确信的情况下预测为真(肿瘤为恶性)。
高查全率意味着尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断。
面对多个阙值参数选择,我们应该使用F1值较高的那系列参数。
几个关键问题
首先,一个人类专家看到了特征值 $x$,能很有信心的预测出$y$值吗?因为这可以证明 $ y$ 可以根据特征值$x$被准确地预测出来。
其次,我们实际上能得到一组庞大的训练集,并且在这个训练集中训练一个有很多参数的学习算法吗?
如果你能做到这两者,那么更多时候,你会得到一个性能很好的学习算法。
Mini-Batch
Mini-Batch是介于批量梯度下降算法和随机梯度下降算法(Stochastic Gradient Descent)之间的算法,每计算常数次(b次)训练实例,便更新一次参数 。
学习率
我们可以通过减小学习率来优化算法。
例如令$\alpha =\frac{常数1}{迭代次数+常数2}$
在线学习(Online Learning)
在线学习的算法与随机梯度下降算法有些类似,我们对单一的实例进行学习,而非对一个提前定义的训练集进行循环。
一旦对一个数据的学习完成了,我们便可以丢弃该数据,不需要再存储它了。这种方式的好处在于,我们的算法可以很好的适应用户的倾向性,算法可以针对用户的当前行为不断地更新模型以适应该用户。
映射化简和数据并行(Map Reduce and Data Parallelism)
如果我们能够将我们的数据集分配给多台计算机,让每一台计算机处理数据集的一个子集,然后我们将计所的结果汇总在求和。这样的方法叫做映射简化(Map Reduce)。
例如,我们有400个训练实例,我们可以将批量梯度下降的求和任务分配给4台计算机进行处理:

很多高级的线性代数函数库已经能够利用多核CPU的多个核心来并行地处理矩阵运算,这也是算法的向量化实现如此重要的缘故(比调用循环快)。
获取更多数据
以文字识别应用为例,我们可以字体网站下载各种字体,然后利用这些不同的字体配上各种不同的随机背景图片创造出一些用于训练的实例,这让我们能够获得一个无限大的训练集。这是从零开始创造实例。
另一种方法是,利用已有的数据,然后对其进行修改,例如将已有的字符图片进行一些扭曲、旋转、模糊处理。只要我们认为实际数据有可能和经过这样处理后的数据类似,我们便可以用这样的方法来创造大量的数据。
有关获得更多数据的几种方法:
- 人工数据合成
- 手动收集、标记数据
- 众包
上限分析(Ceiling Analysis)
我们的文字识别应用中,我们的流程图如下:

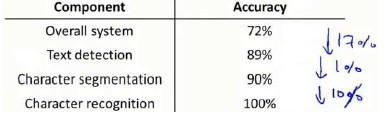
流程图中每一部分的输出都是下一部分的输入,上限分析中,我们选取一部分,手工提供100%正确的输出结果,然后看应用的整体效果提升了多少。假使我们的例子中总体效果为72%的正确率。
如果我们令文字侦测部分输出的结果100%正确,发现系统的总体效果从72%提高到了89%。这意味着我们很可能会希望投入时间精力来提高我们的文字侦测部分。
接着我们手动选择数据,让字符切分输出的结果100%正确,发现系统的总体效果只提升了1%,这意味着,我们的字符切分部分可能已经足够好了。
最后我们手工选择数据,让字符分类输出的结果100%正确,系统的总体效果又提升了10%,这意味着我们可能也会应该投入更多的时间和精力来提高应用的总体表现。
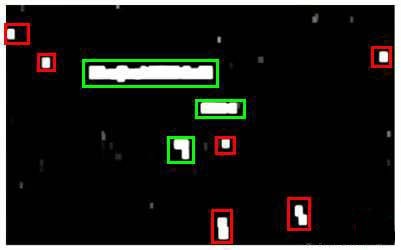
相关应用——图片文字识别(Photo OCR)
图像文字识别应用所作的事是,从一张给定的图片中识别文字。
了完成这样的工作,需要采取如下步骤:
- 文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
- 字符切分(Character segmentation)——将文字分割成一个个单一的字符
- 字符分类(Character classification)——确定每一个字符是什么 可以用任务流程图来表达这个问题,每一项任务可以由一个单独的小组来负责解决:

滑动窗口(Sliding Windows)
滑动窗口是一项用来从图像中抽取对象的技术。假使我们需要在一张图片中识别行人,首先要做的是用许多固定尺寸的图片来训练一个能够准确识别行人的模型。然后我们用之前训练识别行人的模型时所采用的图片尺寸在我们要进行行人识别的图片上进行剪裁,然后将剪裁得到的切片交给模型,让模型判断是否为行人,然后在图片上滑动剪裁区域重新进行剪裁,将新剪裁的切片也交给模型进行判断,如此循环直至将图片全部检测完。
一旦完成后,我们按比例放大剪裁的区域,再以新的尺寸对图片进行剪裁,将新剪裁的切片按比例缩小至模型所采纳的尺寸,交给模型进行判断,如此循环。

滑动窗口技术也被用于文字识别,首先训练模型能够区分字符与非字符,然后,运用滑动窗口技术识别字符,一旦完成了字符的识别,我们将识别得出的区域进行一些扩展,然后将重叠的区域进行合并。接着我们以宽高比作为过滤条件,过滤掉高度比宽度更大的区域(认为单词的长度通常比高度要大)。下图中绿色的区域是经过这些步骤后被认为是文字的区域,而红色的区域是被忽略的。