一天学会深度学习
此为李宏毅(Hung-yi Lee)的Understanding Deep Learning in One Day 课程的笔记。
分为四个部分:
1.深度学习简介(Introduction of Deep Learning)
2.训练深度神经网络的技巧( Tips for Training Deep Neural Network)
3.神经网络的变体(Variants of Neural Network)
4.深度学习下一股浪潮(Next Wave)
一、深度学习简介
(这一章前段主要讲述了神经网络的一些基本知识,不再赘述。)
Universality Theorem告诉我们:任何连续函数$f:R^N \to R^M$都能通过具有一个隐藏层的神经网络实现(只要给定足够多的隐藏神经元)
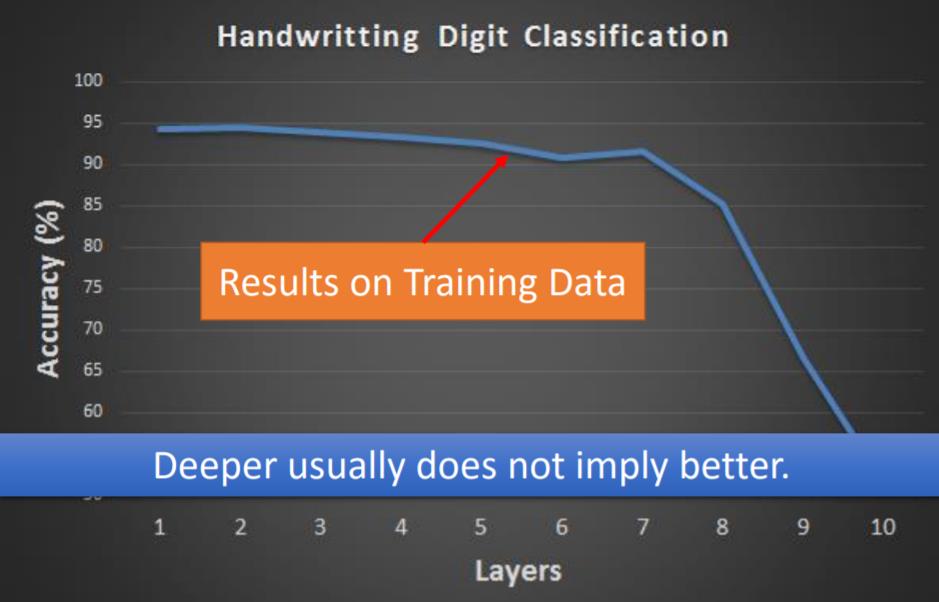
那为什么我们选择使用深层(deep)神经网络而不是浅层但是更fat的神经网络呢?
使用深层神经网络具有更少的感知机,也表现得更好。
此外,深层也意味着模块化(Modularization)。比如一个人脸识别的神经网络,第一次可能是性别分类器,第二次可能是某某特征的分类器,诸如此类。模块化是从数据中自动学习的,无需手动设置。
(另外,也可参考吴恩达《深度学习》课程中“Why deep representations?”部分)
(接下来的后半段是Keras使用教程,不再赘述)
二、训练深度神经网络的技巧
首先虽然过拟合是一个常见问题,但不要总是责怪过拟合,有可能是训练集数据的问题。
为了解决过拟合,我们可以主动获取更多训练集,并创建一些训练集样本(比如手写识别中,我们可以选择将训练样本旋转一定角度)
作为实验,我们还会想测试集中添加噪声。
深度学习的秘诀(Recipe of Deep Learning)
1、选择合适的代价函数
比如,当你使用softmax输出层时,请选择交叉熵( cross entropy)
2、使用Mini-batch
Mini-batch相比原始的梯度下降法更快,但是不一定更准确,其核心思想其实就是并行计算。
3、选择新的激活函数(activation function)
更深的神经网络并不一定更好,可能面对梯度消失(Vanishing Gradient Problem)等问题。
2006年,人们普遍使用 RBM pre-training(Restricted Boltzmann Machine)。
2015年,更多的人使用ReLU。
Rectified Linear Unit (ReLU)
使用原因:
1.计算更快
2.生物学原因
3.带有不同biases的无限(Infinite) sigmoid
4.有利于处理梯度消失的问题
ReLU 的变种:
α也通过梯度下降法学习。
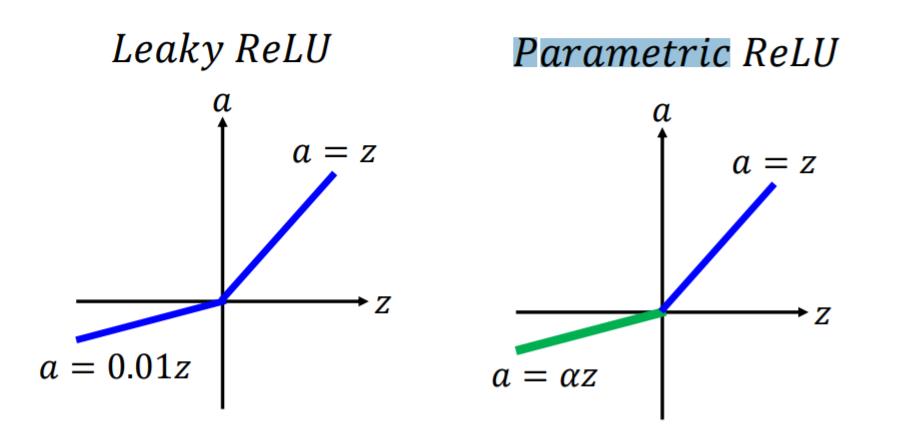
此外还有Maxout,ReLU是Maxout的一个特例。
4、自适应学习速率(Adaptive Learning Rate)
一个流行且简单的想法是:
每隔几代(epochs)就降低学习率
比如可设置$\eta ^t=\eta / \sqrt{t+1}$
注意,学习率不能一刀切,不同参数不同学习率不一定相同。
Adagrad算法:
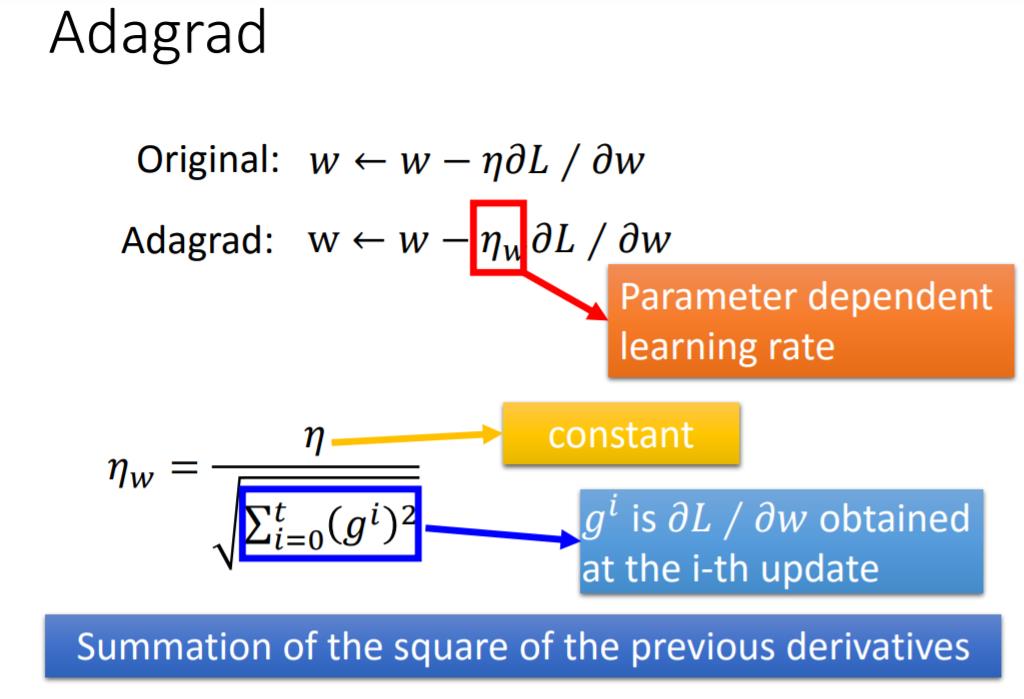
设置全局学习率之后,每次的学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同。
当然还有其他算法。
• Adagrad [John Duchi, JMLR’11]
• RMSprop
• https://www.youtube.com/watch?v=O3sxAc4hxZU
• Adadelta [Matthew D. Zeiler, arXiv’12]
• “No more pesky learning rates” [Tom Schaul, arXiv’12]
• AdaSecant [Caglar Gulcehre, arXiv’14]
• Adam[Diederik P. Kingma, ICLR’15]
• Nadam
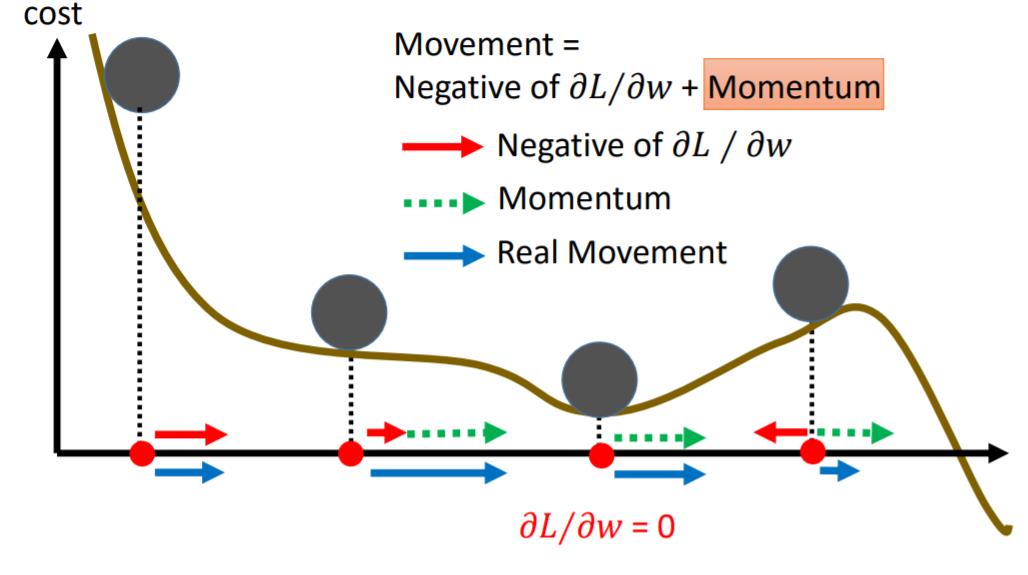
5、动量方法(Momentum)
模拟自然界中的物理过程。仍然不能保证一定达到全局最小值,但有一定希望。
Adam算法:
相当于RMSProp (Advanced Adagrad) + Momentum

6、使用早停法(early stopping)
7、权重衰减(weight decay)
我们的大脑会清除了神经元之间无用的联系。
神经网络也应如此。
权值衰减是正则化的一种技巧。

8、使用Dropout算法
Dropout流程:
每次更新参数前,每个神经元都有p%的可能性退出。
所以,Dropout算法训练一堆不同结构的神经网络。
那为什么Dropout会更好呢?
直观理解:
比如当团队合作时,如果每个人都希望其他partner来完成工作,那么最终什么也做不成。
然而,如果你知道你的partner会退出,你会做得更好。
在测试时,其实没有人中途退出,所以最终取得了不错的成绩。
更多资料:
• More reference for dropout [Nitish Srivastava, JMLR’14] [Pierre Baldi, NIPS’13][Geoffrey E. Hinton, arXiv’12]• Dropout works better with Maxout [Ian J. Goodfellow, ICML’13]
• Dropconnect [Li Wan, ICML’13]
• Dropout delete neurons • Dropconnect deletes the connection between neurons
• Annealed dropout [S.J. Rennie, SLT’14] • Dropout rate decreases by epochs
• Standout [J. Ba, NISP’13]
• Each neural has different dropout rate
三、神经网络的变体
这一部分主要讲述CNN和RNN。
四、下一股浪潮
本节提纲:
•监督学习
•超深层网络(Ultra Deep Network)
•Attention Model
•强化学习
•无监督学习
•图片:认识世界是什么样子
•文本:理解词语的含义
•音频:在没有监督的情况下学习人类语言
监督学习
超深网络:
近年来模型层数逐渐增加。
AlexNet (2012) :8层
VGG (2014) :19层
GoogleNet (2014):22层
Residual Net (2015):152层
超深层网络是多种深层网络的集合。
比如有篇论文:
Residual Networks are Exponential Ensembles of Relatively Shallow Networks
Highway Network也是一种流行的超深层网络。其能自动选取所需层数。
Attention Model
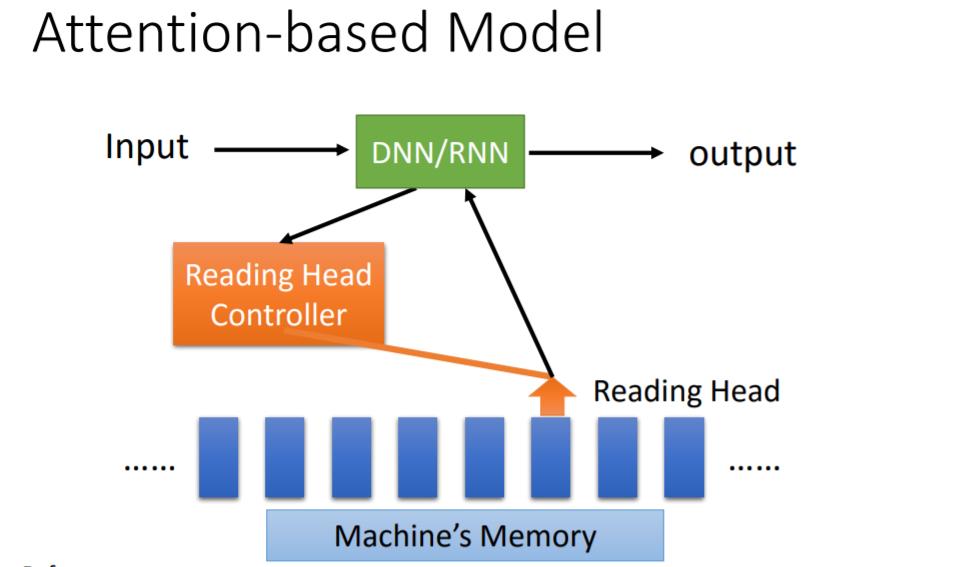
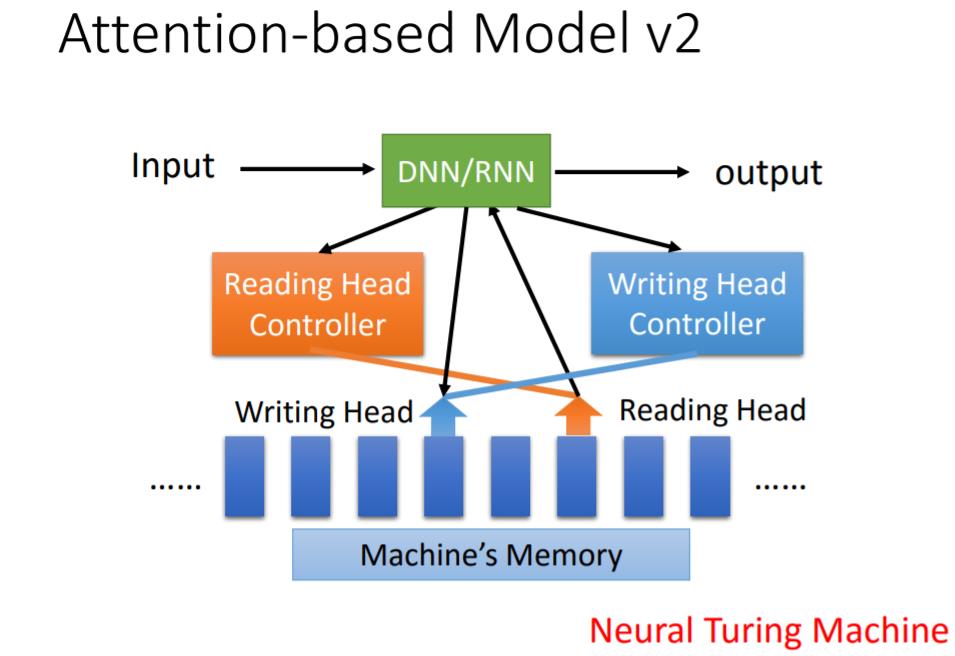
(吴恩达的《深度学习》课程关于这部分讲得更具体,可参考)
强化学习
强化学习是指智能体(Agent)以试错的方式进行学习。像Alpha Go就是监督学习+强化学习的产物。
强化学习的一些困难
1)为了获得更多的长期奖励,牺牲即时奖励可能会更好
2)Agent的行为会影响它接收到的后续数据
一些应用
• Alpha Go, Playing Video Games, Dialogue
• Flying Helicopter
• https://www.youtube.com/watch?v=0JL04JJjocc
• Driving
• https://www.youtube.com/watch?v=0xo1Ldx3L5Q
• Google Cuts Its Giant Electricity Bill With DeepMind-Powered AI
• http://www.bloomberg.com/news/articles/2016-07- 19/google-cuts-its-giant-electricity-bill-with-deepmindpowered-ai
强化学习相关资料
• Lectures of David Silver
• http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Te aching.html
• 10 lectures (1:30 each)
• Deep Reinforcement Learning
• http://videolectures.net/rldm2015_silver_reinfo rcement_learning/
无监督学习
生成图像
训练一个解码器来生成图像是无监督的。
相关方法:
• Variation Auto-encoder (VAE)
• Ref: Auto-Encoding Variational Bayes, https://arxiv.org/abs/1312.6114
• Generative Adversarial Network (GAN)
• Ref: Generative Adversarial Networks, http://arxiv.org/abs/1406.2661
机器阅读
机器在没有监督的情况下,通过阅读大量的文件来学习单词的意思。
声音学习
相关模型:WaveNet (DeepMind)