机器学习之聚类算法
在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签,我们需要据此拟合一个假设函数。与此不同的是,在非监督学习中,我们的数据没有附带任何标签。聚类算法(Clustering)是一种非监督学习算法。
K-means算法
K-means是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K-means是一个迭代算法,假设我们想要将数据聚类成n个组,其方法为:
首先选择$K$个随机的点,称为聚类中心(cluster centroids);
对于数据集中的每一个数据,按照距离$K$个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类。
计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置。
重复步骤2-4直至中心点不再变化。
K-均值算法的伪代码如下:
1 | |
算法分为两个步骤,第一个for循环是赋值步骤,即:对于每一个样例$i$,计算其应该属于的类。第二个for循环是聚类中心的移动,即:对于每一个类$K$,重新计算该类的质心。
K-means 的代价函数
K-means的代价函数(又称畸变函数 Distortion function)为:
$$
J(c^{(1)},…,c^{(m)},μ_1,…,μ_K)=\frac {1}{m}\sum^{m}{i=1}\left| X^{\left( i\right) }-\mu{c^{(i)}}\right| ^2
$$
其中$\mu _c^{(i)}$代表与$x^{(i)}$最近的聚类中心点。
回顾刚才给出的:
K-均值迭代算法,我们知道,第一个循环是用于减小$c^{(i)}$引起的代价,而第二个循环则是用于减小$\mu _i$引起的代价。迭代的过程一定会是每一次迭代都在减小代价函数,不然便是出现了错误。
随机初始化
为了避免使用K-means时出现陷入局部最优,我们通常需要多次(一般为50~1000次)运行K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果。这种方法在$K$较小的时候(2–10)还是可行的,但是如果$K$较大,这么做也可能不会有明显地改善。
选择聚类数
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题,人工进行选择的。
以下是一个可能会谈及的方法。
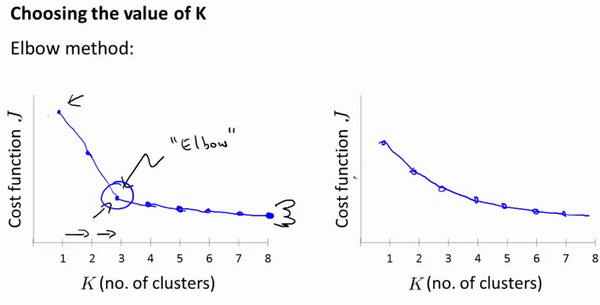
肘部法则:
我们所需要做的是改变$K$值,也就是聚类类别数目的总数。我们用一个聚类来运行K均值聚类方法。这就意味着,所有的数据都会分到一个聚类里,然后计算成本函数或者计算畸变函数$J$。$K$代表聚类数字。
我们可能会得到一条类似于这样的曲线。像一个人的肘部。这就是“肘部法则”所做的,让我们来看这样一个图,看起来就好像有一个很清楚的肘在那儿。好像人的手臂,如果你伸出你的胳膊,那么这就是你的肩关节、肘关节、手。这就是“肘部法则”。你会发现这种模式,它的畸变值会迅速下降,从1到2,从2到3之后,你会在3的时候达到一个肘点。在此之后,畸变值就下降的非常慢,看起来就像使用3个聚类来进行聚类是正确的,这是因为那个点是曲线的肘点,畸变值下降得很快,$K=3$之后就下降得很慢,那么我们就选$K=3$。当你应用“肘部法则”的时候,如果你得到了一个像上面这样的图,那么这将是一种用来选择聚类个数的合理方法。
但是通常我们得到的是右图,很难看出”肘部“的位置。所以“肘部法则”并不是一个非常常用的法则。