一些简单的串的模式匹配算法汇总
串的模式匹配算法在许多领域,包括爬虫、机器学习等都有重要应用。以下列了一些串的模式匹配算法:
1.Brute-Force算法(暴力算法)
正如其名,非常直接且简单。
首先将匹配串和模式串左对齐,然后从左向右一个一个进行比较,如果不成功则模式串向右移动一个单位。
例:
设置两个指针,一个匹配串指针i,一个模式串指针j
一开始i=1,j=1
第一个不符合,i++
…当i=3时,
匹配串 :abcbcsdxzcxx
模式串:cbcac
符合i++,j++,依旧符合i++,j++,直到i=6,j=4,不符合,i回退到3+1,j回退到1
…
该算法的缺陷是匹配串指针i会不断地回退,使时间复杂度较高。每次进行,对模式串的错误没有记忆,相当于每次模式串都是全新。接下来的算法基本都利用了模式串匹配的错误信息,从而避免了匹配串指针i不会一直回退。
2.KMP算法
相关论文:
Knuth D.E., Morris J.H., and Pratt V.R., Fast pattern matching in strings, SIAM Journal on Computing, 6(2), 323-350, 1977.
以下来自:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html

首先,字符串”BBC ABCDAB ABCDABCDABDE”的第一个字符与搜索词”ABCDABD”的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。

因为B与A不匹配,搜索词再往后移。

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。

接着比较字符串和搜索词的下一个字符,还是相同。

直到字符串有一个字符,与搜索词对应的字符不相同为止。

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把”搜索位置”移到已经比较过的位置,重比一遍。
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是”ABCDAB”。KMP算法的想法是,设法利用这个已知信息,不要把”搜索位置”移回已经比较过的位置,继续把它向后移,这样就提高了效率。
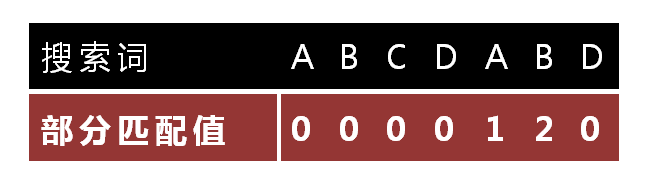
怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
已知空格与D不匹配时,前面六个字符”ABCDAB”是匹配的。查表可知,最后一个匹配字符B对应的”部分匹配值”为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2(”AB”),对应的”部分匹配值”为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
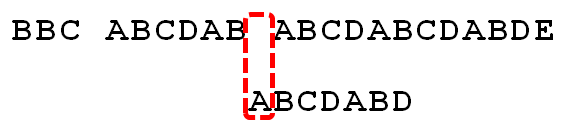
因为空格与A不匹配,继续后移一位。

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:”前缀”和”后缀”。 “前缀”指除了最后一个字符以外,一个字符串的全部头部组合;”后缀”指除了第一个字符以外,一个字符串的全部尾部组合。
“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例,
- “A”的前缀和后缀都为空集,共有元素的长度为0;
- “AB”的前缀为[A],后缀为[B],共有元素的长度为0;
- “ABC”的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- “ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- “ABCDA”的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为”A”,长度为1;
- “ABCDAB”的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为”AB”,长度为2;
- “ABCDABD”的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
“部分匹配”的实质是,有时候,字符串头部和尾部会有重复。比如,”ABCDAB”之中有两个”AB”,那么它的”部分匹配值”就是2(”AB”的长度)。搜索词移动的时候,第一个”AB”向后移动4位(字符串长度-部分匹配值),就可以来到第二个”AB”的位置。
(完)
3. Boyer-Moore算法
相关论文:
R.S.Boyer, J.S.Moore, A fast string searching algorithm , Communications of the ACM,20(10):762-772 ,1977
来自http://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html

假定字符串为”HERE IS A SIMPLE EXAMPLE”,搜索词为”EXAMPLE”。

首先,”字符串”与”搜索词”头部对齐,从尾部开始比较。
这是一个很聪明的想法,因为如果尾部字符不匹配,那么只要一次比较,就可以知道前7个字符(整体上)肯定不是要找的结果。
我们看到,”S”与”E”不匹配。这时,**”S”就被称为”坏字符”(bad character),即不匹配的字符。**我们还发现,”S”不包含在搜索词”EXAMPLE”之中,这意味着可以把搜索词直接移到”S”的后一位。

依然从尾部开始比较,发现”P”与”E”不匹配,所以”P”是”坏字符”。但是,”P”包含在搜索词”EXAMPLE”之中。所以,将搜索词后移两位,两个”P”对齐。
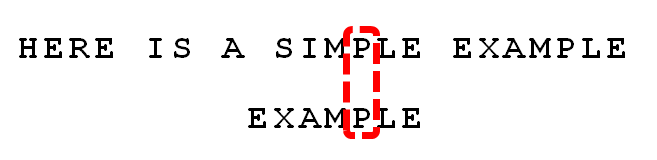
我们由此总结出**”坏字符规则”**:
后移位数 = 坏字符的位置 - 搜索词中的上一次出现位置
如果”坏字符”不包含在搜索词之中,则上一次出现位置为 -1。
以”P”为例,它作为”坏字符”,出现在搜索词的第6位(从0开始编号),在搜索词中的上一次出现位置为4,所以后移 6 - 4 = 2位。再以前面第二步的”S”为例,它出现在第6位,上一次出现位置是 -1(即未出现),则整个搜索词后移 6 - (-1) = 7位。

依然从尾部开始比较,”E”与”E”匹配。
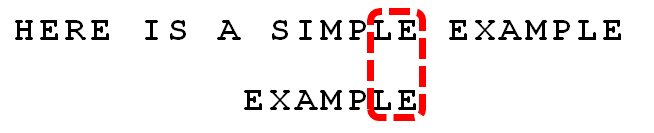
比较前面一位,”LE”与”LE”匹配。
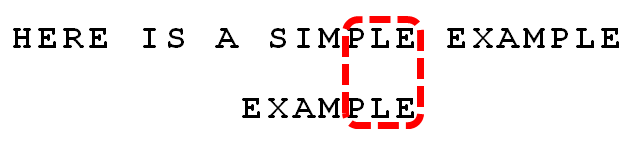
比较前面一位,”PLE”与”PLE”匹配。

比较前面一位,”MPLE”与”MPLE”匹配。**我们把这种情况称为”好后缀”(good suffix),即所有尾部匹配的字符串。**注意,”MPLE”、”PLE”、”LE”、”E”都是好后缀。
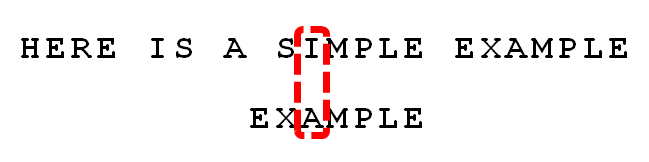
比较前一位,发现”I”与”A”不匹配。所以,”I”是”坏字符”。
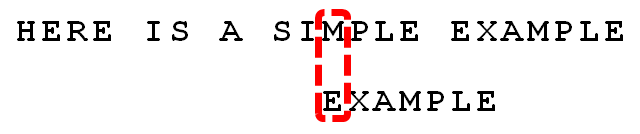
根据”坏字符规则”,此时搜索词应该后移 2 - (-1)= 3 位。问题是,此时有没有更好的移法?
我们知道,此时存在”好后缀”。所以,可以采用**”好后缀规则”**:
后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置
举例来说,如果字符串”ABCDAB”的后一个”AB”是”好后缀”。那么它的位置是5(从0开始计算,取最后的”B”的值),在”搜索词中的上一次出现位置”是1(第一个”B”的位置),所以后移 5 - 1 = 4位,前一个”AB”移到后一个”AB”的位置。
再举一个例子,如果字符串”ABCDEF”的”EF”是好后缀,则”EF”的位置是5 ,上一次出现的位置是 -1(即未出现),所以后移 5 - (-1) = 6位,即整个字符串移到”F”的后一位。
这个规则有三个注意点:
(1)”好后缀”的位置以最后一个字符为准。假定”ABCDEF”的”EF”是好后缀,则它的位置以”F”为准,即5(从0开始计算)。
(2)如果”好后缀”在搜索词中只出现一次,则它的上一次出现位置为 -1。比如,”EF”在”ABCDEF”之中只出现一次,则它的上一次出现位置为-1(即未出现)。
(3)如果”好后缀”有多个,则除了最长的那个”好后缀”,其他”好后缀”的上一次出现位置必须在头部。比如,假定”BABCDAB”的”好后缀”是”DAB”、”AB”、”B”,请问这时”好后缀”的上一次出现位置是什么?回答是,此时采用的好后缀是”B”,它的上一次出现位置是头部,即第0位。这个规则也可以这样表达:如果最长的那个”好后缀”只出现一次,则可以把搜索词改写成如下形式进行位置计算”(DA)BABCDAB”,即虚拟加入最前面的”DA”。
回到上文的这个例子。此时,所有的”好后缀”(MPLE、PLE、LE、E)之中,只有”E”在”EXAMPLE”还出现在头部,所以后移 6 - 0 = 6位。
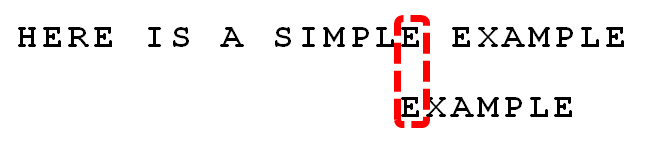
可以看到,”坏字符规则”只能移3位,”好后缀规则”可以移6位。所以,Boyer-Moore算法的基本思想是,每次后移这两个规则之中的较大值。
更巧妙的是,这两个规则的移动位数,只与搜索词有关,与原字符串无关。因此,可以预先计算生成《坏字符规则表》和《好后缀规则表》。使用时,只要查表比较一下就可以了。
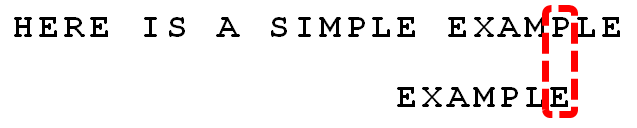
继续从尾部开始比较,”P”与”E”不匹配,因此”P”是”坏字符”。根据”坏字符规则”,后移 6 - 4 = 2位。

从尾部开始逐位比较,发现全部匹配,于是搜索结束。如果还要继续查找(即找出全部匹配),则根据”好后缀规则”,后移 6 - 0 = 6位,即头部的”E”移到尾部的”E”的位置。
(完)
4.Horspool算法
相关论文:
Horspool R.N., 1980, Practical fast searching in strings, Software - Practice & Experience, 10(6):501-506
Horspool算法的一个独特之处是它的模式串是尾匹配的(即从右到左)
例:
我们将在匹配串寻找字符使得模式串能从右往左匹配。(1)
模式串的尾是e,匹配到第一个e,这已经是匹配串的第11个字符。
匹配串 :Here is a excellent example
模式串: example
这是我们从右往左匹配:
空格与l不匹配,模式串将从不匹配的那个字符开始从右向左寻找匹配串中不匹配的字符的位置,模式串里没有空格,所以移动一个模式串长度的单位
匹配串 :Here is a excellent example
模式串: example
不匹配,按(1)操作。
逐次类推。
(完)
5.Sunday算法
相关论文:
Daniel M. Sunday, A very fast substring search algorithm, Communications of the ACM, v.33 n.8, p.132-142, Aug. 1990
Sunday算法和Horspool算法类似,都是尾匹配,不过匹配方式略有不同,不是找匹配串中不匹配的字符在模式串的位置,而是直接找最右边对齐的右一位的那个字符在模式串的位置
例:
我们将在匹配串寻找字符使得模式串能从右往左匹配。
模式串的尾是e,匹配到第一个e,这已经是匹配串的第11个字符。
匹配串 :Here is a excellent example
模式串: example
空格和l没有匹配上,寻找匹配串右一个字符在模式串的位置。
匹配串 :Here is a excellent example
模式串: example
继续匹配,发现匹配串右一个字符在模式串里找不到,跳过去
匹配串 :Here is a excellent example
模式串: example
继续匹配,匹配串右一个字符为l
匹配串 :Here is a excellent example
模式串: example
(完)
更高级的串模式匹配算法还有以下几种:
6.有限自动机算法
7.Rabin-Karp算法
相关论文:
Rachard M.Karp and Michael O.Rabin.Efficient randomized pattern-matching algorithms.IBM Journal of Research and Development,31(2):249-260,1987.
利用哈希值。
8.Galil-Seiferas 算法
相关论文:
Zvi Galil and.Joel Seiferas. Time-Space-Optimal String Matching. Journal of Computer And System Sciences, 26(3),:280-294 (1983)
该算法基于重复因子的字符串匹配。该算法是一个奇妙的线性时间字符串算法,除了匹配串和模式串所需的存储空间外,只需要O(1)的额外存储空间。
参考资料:
[1]https://blog.csdn.net/xiaodu93/article/details/39209421.
[2]算法导论(Introduction to Algorithms).